


Issue #24 – Technology to Scale Your Analytics More Effectively
Issue #24 – Technology to Scale Your Analytics More Effectively
Build vs. buy. Open- vs. closed-source. What's the right approach to building cost-effective analytical solutions

Read time: 11 minutes
It’s incredible how many organisations are still not getting value from their data and analytical activities.
They’ve invested a ton of money in a team, a data platform and different tools/ technology, but problems are still arising.
Some call it growing pains, but many companies face this widespread challenge when scaling their data operations. They:
Lack a coherent strategy to guide their technology stack decisions
Are confused about the types of data tools available and how they interact with one another
Are constantly bombarded with new vendor options and approaches, making it hard to select the right solution for their needs
Don’t think about and match up the underlying people and process perspectives with these technology decisions
And in the end, you need to get results quickly; scalability and quick wins are essential to proving the value of data to leadership!
So how should companies balance their options to get real value from their analytics and data investments?
It’s time to start taking a more thoughtful approach and looking at the whole spectrum of technology options, understanding how to streamline your company’s analytics against your business needs, matched with your unique company profile. Let’s dig in!
The Reality of Most Data Teams/ Companies
Let’s face it—most organisations aren’t Meta, Netflix, or Google.
They don’t have billion-dollar budgets, massive data teams, or a data-first culture inherent in their business model.
Yet many companies approach their data infrastructure as if running at that scale, investing in expensive tools or platform builds like Snowflake or Databricks for relatively minimal analytical requirements (precisely because others are doing it, and they think they should too)!
This leads to high vendor costs, inefficient resource use, and additional tooling that often doesn’t serve the business’s specific needs. I’ve seen organisations buy into the promise of "quick analytics" only to face steep learning curves, poor customizability, and a lack of resources to optimise their tools properly.
There are also immense pressures to deliver analytics quickly—especially from non-data leaders who may not fully grasp the complexity and nuance of analytics projects. So, they throw money at tools that promise to deliver magical results overnight. The truth is there are five recurring problems with this approach:
High Upfront Costs – Most vendor-focused tools require significant investment or long-term contracts (especially with the larger players), which is especially problematic for smaller or newer organisations
Speed to Scale – Implementing these systems takes time, and scaling effectively requires careful planning
Customizability – Vendor solutions often don’t fit bespoke business needs, limiting flexibility
Resource Constraints – With limited time, data teams often lack the technical resources and expertise to optimise the solution and manage these tools
Fragmented Integration – Multiple tools often require manual or cumbersome integrations, creating inefficiencies across the data pipeline
Instead of jumping on the latest tech bandwagon, data teams—particularly those in smaller or more immature organisations—need to consider their tooling more holistically and strategically.
For example, I was just at a Big Data LDN talk by Deepan Ignaatious (a Product Manager at DoubleCloud), where he examined both the Vendor Locked-in and the fully Open Source approach. These are the two most common approaches to standing up your initial analytical projects/ stacks. Unfortunately, there are downsides that most companies don’t think about.
So let’s dive into how to approach those!
Consider the Technology You Need
When evaluating the right technology stack, the first step is holistic thinking. There are five fundamental categories of data tooling I’ve previously outlined as mandatory:
Storage – Where your raw and processed data lives
Data Processing & Transformation – Tools for transforming raw data into usable formats
Orchestration – Managing workflows and processes to ensure everything runs efficiently
ETL Tooling – Extract, transform, and load data across your systems
Analytics, Consumption & Visualisation Tools – Allowing end-users to derive insights from the data
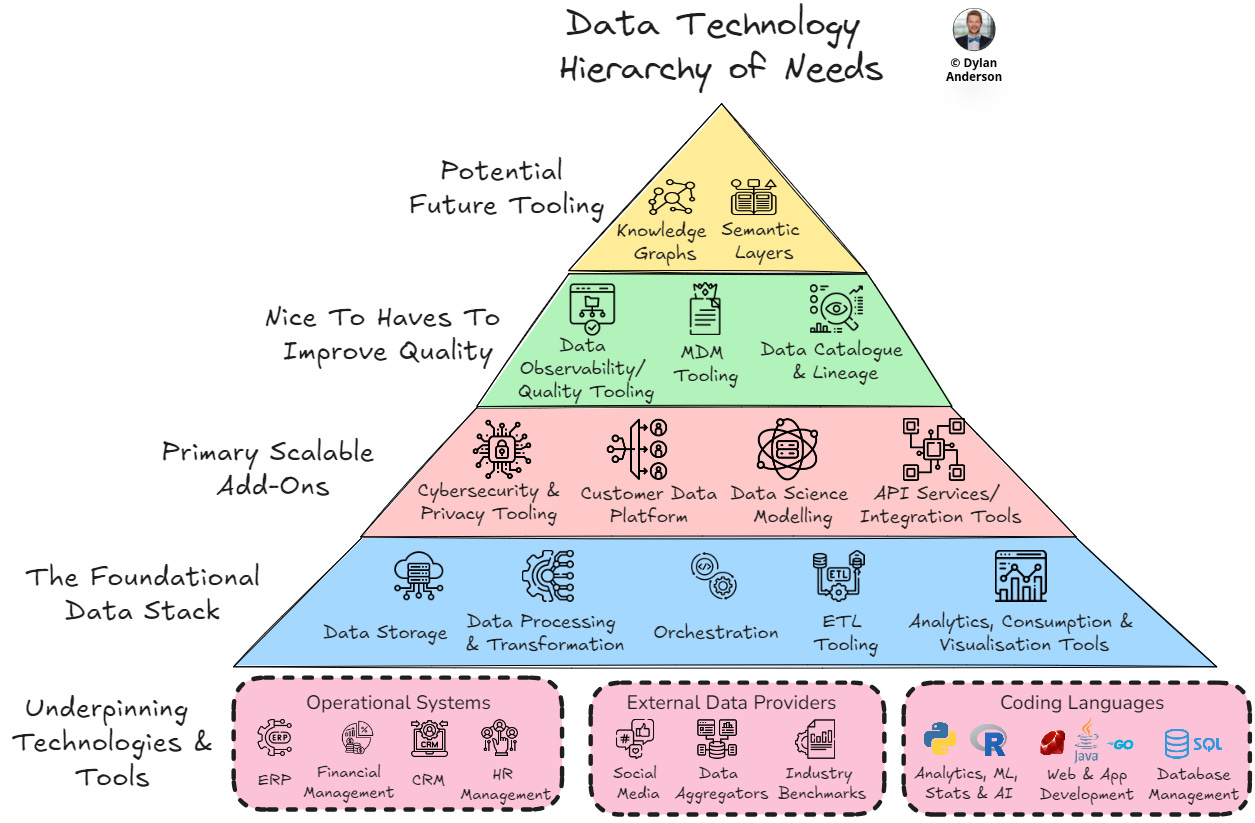
While it might be tempting to invest in an S3 bucket, connect it to Databricks for processing, and feed it into Tableau for visualisation, companies must be realistic about their actual needs and budget constraints. As Deepan highlighted in his talk, relying too heavily on vendor solutions can lock you into their ecosystems, limit customizability, create integration complexity and lead to high costs.
The other option is to build bespoke analytics projects via open-source solutions. Developing via services like ClickHouse, Kafka, and Airflow on your cloud provider can reduce costs and help you better customise solutions to fit your requirements. However, this also presents challenges, particularly regarding integration, scalability/ tooling management, and implementing observability.
Before signing up for expensive tools or starting from scratch with open-source options, it’s crucial to evaluate what’s necessary for your organisation’s data goals and capabilities.
This gets us into the age-old debate of Build vs. Buy…
Build vs. Buy and Open vs. Closed Source Debates
The Build vs. Buy debate has existed for ages. But there should be another consideration to make (especially as data solutions/ tooling has become more accessible): Open vs. Closed source approaches.
In reality, every company builds with open-source technology like the ones mentioned above. In short, it often performs better than closed-source vendor technology and has a strong community behind it.
However, choosing Build does not equal open-source, and Buying does not equal closed-source. Today, many companies open-source their code but provide premium options to add storage space, speed up usage, or help design/ develop solutions. You can also build custom tooling within a vendor’s menu of data analytics/ science solutions. Therefore, you can buy open-source or build within closed-source/ vendor environments.
This makes it more of a technology spectrum of optionality, as illustrated below:

Within this spectrum, we have four categories of how you might approach your technology needs. In the image, I have discussed the pros and cons of each approach, and below, I will summarise what each one offers and why you might choose it:
Build & Open Source – Offers maximum flexibility and low costs but requires significant technical expertise, resources and ongoing maintenance. Select this approach when:
You need a highly specialised stack or tool that off-the-shelf solutions can't provide
You want to build core competencies in particular technologies
Cost is a prohibitor to buying, and the solution is not super complex
Build & Closed Source – Allows custom solutions built on solid vendor foundations. It is easy to access their support but can become costly in terms of licensing and difficult to scale. Select this approach when:
You are dealing with highly sensitive or regulated data that requires complete control from tools that have strong vendor security foundations/ support
Vendors offer relevant foundational tooling/ technology for specific use cases you are looking to build
Differentiator vendor-owned technologies exist in the marketplace that can be further customised for your use cases
Buy & Open Source – Premiumisation of free tooling that includes customised solutions, increased management/ oversight and additional features. Has lower upfront costs and flexibility without vendor lock-in, but integration and overall support may be limited. Select this approach when:
You want proven, flexible open-source solutions that can be customised if needed
You have the expertise and resources to integrate and maintain various open-source tools
You need management of existing open-source tools or expertise to use them more effectively
Buy & Closed Source – The most user-friendly option with tons of support but also the most expensive, with lock-in risks and vendor dependency. Select this approach when:
There is a specific niche use case that the vendor’s solution addresses
You need a reliable, integrated stack that works out of the box and have the budget for higher costs (for both today and tomorrow as you scale)
You lack the expertise and data resources for extensive customisation and maintenance.
It is worth noting that you don’t have to take one approach for all tools/ technologies. Often, a company will purchase a closed-source storage option but build ML tooling based on open-source technologies (e.g., TensorFlow). Or have a largely Open-Source technology stack to reduce costs managed by a company like DoubleCloud to improve scalability, manage security, and maintain performance. That’s why it is crucial to understand what reason you need to buy/ build for and what the benefits of each approach are for that specific technology.
While all combinations have merits, the right decision ultimately depends on your organisation’s effort-to-value trade-off. I’ve mentioned value vs. effort for data use cases before, but this scale is also possible for technology choices, especially considering the spectrum mentioned above. I’ve slightly renamed it (Potential Value vs. Purchase Considerations) to better align with the context of technology decisioning.

Essentially, if the downside of the purchase considerations (cost, resources, time, etc.) is significantly higher than the potential value (insights, revenue uplift, etc.) generated, then it’s not the right fit. The goal is to reduce friction and difficulties within the purchase/ build while maximising value.
Scaling Analytics Effectively with Optimised Infrastructure
Considering all this, I want to return to scalability and efficiency in analytics.
Your perfect technology stack will all depend on the context of what your organisation does and what it needs from its data tools
For smaller organisations who want to scale their analytics for immediate value, I believe the build and open-source side of the spectrum can provide the greatest upside given the flexibility, cost benefits and long-term control that most small data teams need.
However, there are significant challenges, including:
Expertise in the tooling to manage it effectively
High resource requirements to handle the ongoing maintenance of these tools.
Careful attention to integration and workflow orchestration across the stack (especially true with open-source builds)

This is where it is possible to venture into the Buy territory to handle some of those challenges. One such product is a managed platform like DoubleCloud (which I mentioned above).
DoubleCloud integrates the most popular open-source tools into a unified platform, offering businesses scalability, cost-efficiency, and the flexibility to build tailored solutions. The benefits include:
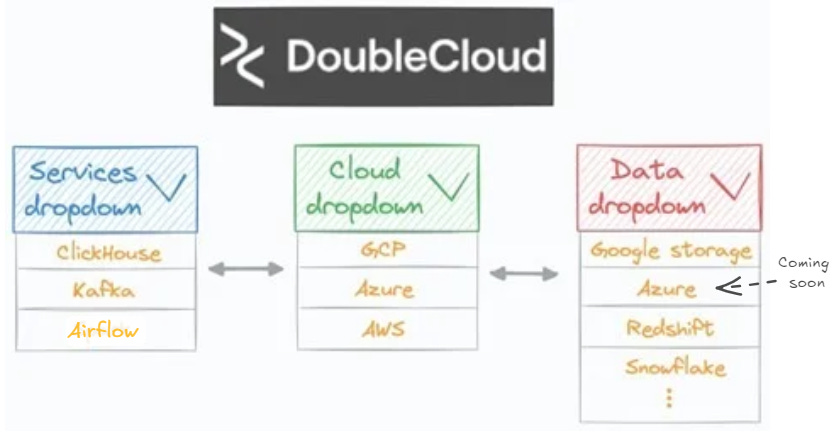
Integration Guidance – DoubleCloud’s platform allows you to streamline the integration of various tooling stacks used across different steps. This is basically like picking different technologies from a dropdown menu to integrate your services, cloud and data, bypassing the complexity when creating your technical architecture
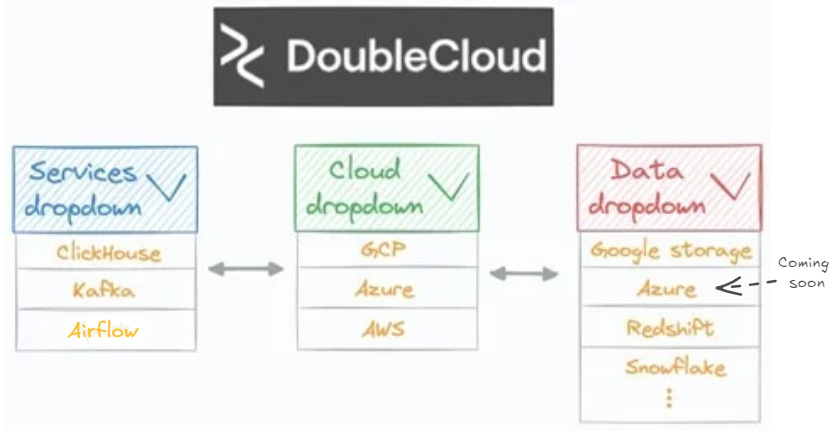
DoubleCloud allows you to pick your tech and it deals with the integration challenges. Image from Avi Chawla here Scalability For Analysts – Often analysts don’t have access to engineers to help build the pipelines or deal with the above integration challenges. Analysts can easily visualise data within DoubleCloud to reduce time to value from days to hours by providing that integration and standardising the workflow. Check out this article by Avi Chawla on the technical details of how he did it
Cost Optimisation – Due to the focus on scalability and real-time analytics, DoubleCloud’s offering is more tailored to optimising your own stack and increasing efficiency through better data integration. Augmenting your existing stack by improving integration functionality and leveraging real-time processing power can reduce costs while increasing speed, like it did for Lsports (a real-time sports data solutions company). The platform is also highly transparent with what your tooling usage is costing, which is information that can be hard to find in vendor-owned ecosystems
Managed Performance with Open-Source – I see many companies hire out consultancies for managed services, which can be expensive. Having technology and a support team do this is a lot more cost-efficient and reduces the complexity of keeping on top of open-source technology or needing to hire resources to manage specific tools, all while getting the benefits of leading tools like ClickHouse, Kafka, or Airflow
Real-time Focused – Like many SaaS companies, DoubleCloud has a niche. They focus on integrating leading open-source tools for real-time analytics. Companies may initially opt for Snowflake because they’ve heard of it, but don’t realise that it’s a lot less efficient and more expensive to run real-time analytics on Snowflake than ClickHouse
As a consultant, I’ve seen too many teams attempt to mimic the approaches of companies 20-50x their size. It doesn’t work.
This is one of the main reasons I partnered with DoubleCloud to write this article. No two companies are alike in the Data Ecosystem, and many organisations can scale their analytics much better if they think more about the types of tools they use and how they integrate them.
Whether you choose DoubleCloud, go fully open-source or find another vendor to solve your needs, the key is to choose your technology partners and tools wisely. Success lies in selecting tools that fit your company’s needs and strategically thinking about your data infrastructure. Don’t just follow trends and try to be like META or Netflix—tailor your decisions to what works best for your unique business context.
In today’s world, scaling your analytics isn’t just adding more tools. It’s about building a platform that aligns with your strategy, fits within your budget, and enables growth without unnecessary complexity.
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). See you amazing folks next week!
I partnered with DoubleCloud to bring you this article on a genuine problem I see within the Data Ecosystem. I believe DoubleCloud is helping companies scale their analytics (especially real-time), and there is a fit for it within many organisations! Like and comment on this to support my newsletter (and keep the The Data Ecosystem paywall from ever going up)