

Issue #22 – Deciding on your Data Platform Philosophy
Going beyond the buzzwords to help you chart your Data Platform solution

Read time: 13 minutes
The most extensive and expensive decision data teams make is: “What does our Data Platform look like?”
As I explained in last week’s article, there is no best answer.
The Data Platform is a nebulous term that encapsulates so much yet means so little. On the one hand, it refers to the core data technologies within an organisation's stack. On the other hand, it gets used ad nauseam and means nothing to anybody anymore.

What is worse is that despite this dichotomy, every data team has to decide: “What does our Data Platform look like?”
That is what this article is about: helping you understand the different philosophies of data platforms, including how these align with and impact the crucial People, Process, Technology and Data elements.
Recap – What is a Data Platform?
If you haven’t read them, read my two articles on the Data Technology Landscape and Data Platform Terminology. Both go into a lot more detail about the types of technology that exist in the data industry and what defines a Data Platform.
If you don’t want to read them now, fear not. Here is a brief overview of what a data platform is and what it should do.
In essence, a Data Platform should make sense of data.
It does this by:
Empowering business users to make better decisions
Breaking down data silos
Ensuring consistency of data across the organisation
Supporting a company’s growth
Adhering to compliance and regulatory requirements
Each data platform should have three main components: (1) A central platform to bring in, clean, store and curate the data; (2) management and governance tools to secure the data and ensure it is of high enough quality to input into analytics; and (3) analytical and consumption tooling to do advanced analysis and visualise data/ insights for business and data users
Below is a helpful graphic I created for my first Data Platform article:

Making sense of your data within the platform largely follows this process, regardless of how your tech is set up or what industry you work in.
I’ve delivered countless data strategy and architecture projects across dozens of industries, and the fact that most companies follow the same dataflow process within their platform makes me confident in this statement.
Data Platform Philosophies
Despite that, the different philosophies and approaches to one’s data platform create another level of confusion.
I mean, if you think the abstract definition and multitude of technologies make Data Platforms hard to understand, wait until you get into the different approaches companies take.

In my mind, there are four philosophies for setting up a data platform:
Centralised
Decentralised/ Mesh
Hybrid/ Hub & Spoke
Fabric
Before defining what they are, how they are structured, and the pros/ cons of each philosophy, it is worth mentioning that these approaches closely mimic the three common data organisational structures you see (depicted below).

This shouldn’t be surprising in the least. People and processes (two critical components of the org structure/ op model) underpin the functionality of data platform technology and facilitate the data flows within the ecosystem.
To succeed, they must all operate symbiotically; without one, the others will fail.
So, when considering your data platform technology approach and how data should flow to different teams, you must first examine the existing organisational structure/ operating model. I wrote about both these topics a few months ago, so check both articles below for more details in this area. I will also discuss this subject more in the last section of this article.


With the people and process in mind, let’s examine how technology and data are structured in the four platform philosophies:
Centralised Data Platform
The basic premise of a centralised data platform is managing all data in one place, from storage and compute to governance and analytics. Centralised platforms are more straightforward in nature, reflecting the classic storage architectures when data was held on-premise. Nowadays the data platform is typically in a cloud warehouse or lake stored in the cloud. Without multiple teams or platforms to worry about, this centralised platform reduces data silos and helps create a single source of truth. This oversight of accurate data extends to governance, security and management, leading to a simplification of rules.

However, with growing data needs it can be hard to manage all data in a centralised way, especially for global organisations with international teams and divisions. Access and analytical requests can also become difficult, as business teams have to request access to data and petition for the development of new solutions. This limits the ability for agile execution and enterprise-wide data democratisation that every company aspires for.
Decentralised/ Mesh Approach
The decentralised approach (or, more commonly, the Data Mesh) is on the opposite side of centralisation. The mesh was the answer to a centralised data platform's bottlenecks and waterfall realities. Here, data is treated as a product and managed in different domain teams, placing responsibility closer to business stakeholders and making it easier to curate data for high priority use cases without waiting on (or justifying it to) the centralised data team. As Crishantha Nanayakkara describes, the data mesh is more of an architectural approach to processes rather than a technology stack.
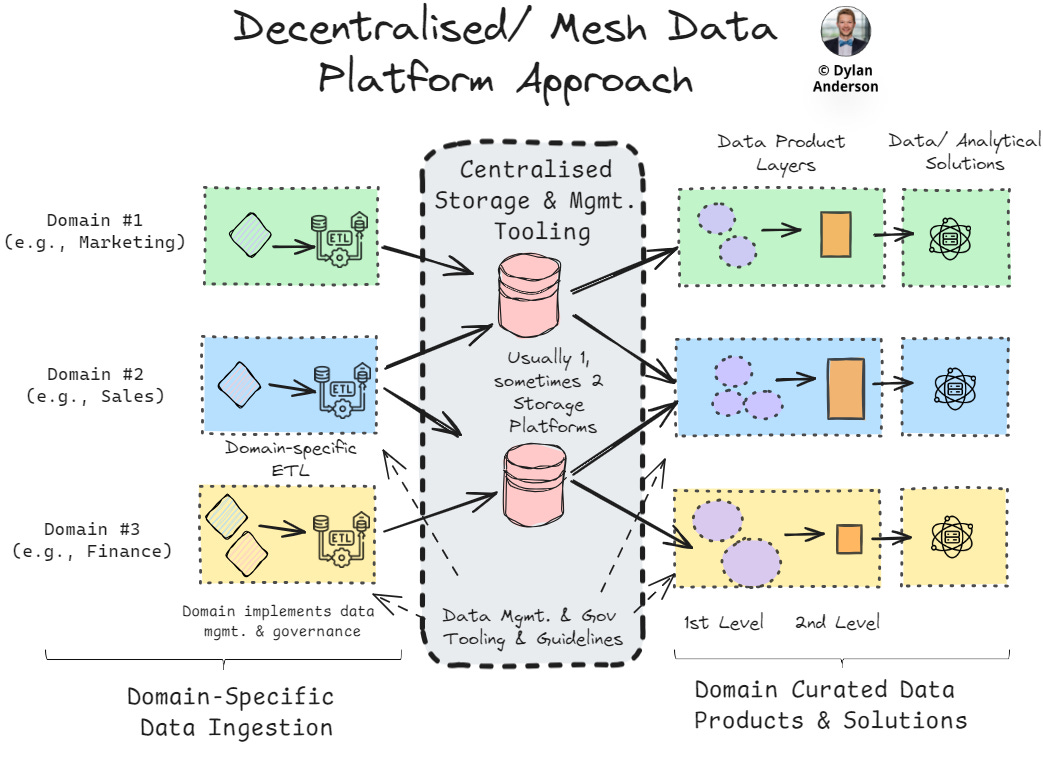
Due to this non-adherence to a uniform tech stack, a mesh platform (from the technology perspective) can look and feel different by organisation. Regarding the storage and processing layers of a platform, most decentralised data teams still operate with a centralised layer. While this is not pure decentralisation, this structure reduces cost and complexity. Other than that, decentralisation holds, specifically the adoption of a self-serve architectural philosophy (self-service as a platform as phrased by Jake Wilson). Data engineering, analytics, and science are domain-specific, meaning different teams may use different technologies and approaches to build their own data ‘products’ and solutions. The one toss-up technology within the platform is data management and governance tools, which are often ubiquitous across the enterprise but used differently with unique underlying processes by domain.
While the ‘data-as-a-product’ approach ensures that data is curated to the business needs and analytical solutions are more customisable, scalable and flexible, there is significant room for duplication and siloed tooling/ data in a mesh architecture. Technology is often used in different ways, and vendor costs can quickly increase without efficient ways of working processes. This is especially true of data governance and management, which is process and communication-reliant. Lastly, the diversified technology and data approaches require specialisation in each domain, leading to larger teams than other platform philosophies.
Hybrid/ Hub & Spoke
The hybrid/ hub and spoke model is the most common model. As I mentioned previously, most data mesh platforms have some semblance of this approach inherent in them. Typically, this consists of a centralised platform that manages core data functions (think data management tooling, processing, storage, security layer). At the same time, analytical solutions are built on domain-specific spokes to increase customizability, relevancy, and proximity to business stakeholders. How companies do this differs, but usually this involves domain-specific data analysts or scientists building relevant data products within the business domain.

The core technology principle of a hybrid approach is ensuring the foundational tooling of data product/ solution design are centralised, while business domains own product delivery and development, allowing for customisation. This usually entails a centralised technology and data management/ governance approach across the enterprise, with a consistent view of the tech stack and trust in the data. In addition, the ‘hub’ acts as a centralised centre of excellence, providing process standards and expertise. This centralised foundational knowledge provides a resource for data analysts & scientists to better design and build data products, leveraging the hub’s data model, management principles, and team experience.
A hybrid model is often more cost-efficient at a platform level. However, tooling duplication does happen in the spokes, especially without a technology strategy (which no companies spend time building). The technology can be challenging to set up as technology choices for the hub and spokes require agreement between business and data teams, especially since the business domains have some ownership. This creates a large grey area and infighting for resources, especially by teams who don’t understand data. Like any other option, processes, people, and change management are crucial to making this work.
Fabric
The Data Fabric platform philosophy is confusing, especially because Microsoft stole and branded the name as a product. Fabric builds on the other three philosophies and binds it using metadata at scale, making data discoverable through a data catalogue (or similar tool). The data catalogue defines and exposes the data and its characteristics, creating a unified layer of data across the enterprise—the fabric, so to speak. A key component to doing this effectively is designing a data model or architecture that facilitates this interoperability between data. Within this, the data management remains centralised, but the accessibly designed data catalogue provides scalability and flexibility for business teams to identify their requirements.
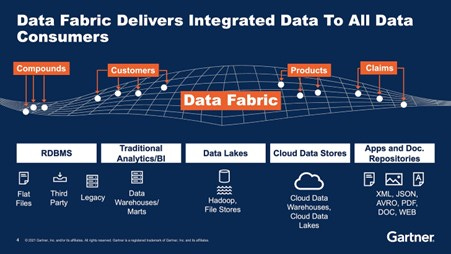
According to a few blogs, the steps to set up a data fabric are to:
Identify key sources of metadata
Build a data model MVP
Align data to the model
Set up consumer analytical applications (which might be set up through data contracts)
Repeat for new data assets
While this philosophy has potential, it doesn’t significantly deviate from the other three approaches as the platform is still designed and set up similarly. The main difference is the additional connectivity and searchability layer available through the metadata and catalogue. Operationally, data access requests may still go through one team (centralised), leading to wasted time or a lack of centralised knowledge of the business needs. Or business teams may add data to the fabric model (decentralised), which could result in duplicated and poor quality data. The complexity and ambiguity of setting up a data fabric platform remain, especially when considering maintenance and management of the integrations. So, despite organisations discussing it as a silver bullet, I don’t think it's quite there yet.
Data Platform Migrations, Amendments & Evolutions
Despite everything I have written, your organisation will likely not build a data platform from scratch.
You probably have some SQL server database or storage bucket, potentially enhanced by a processing/ transformation tool or platform. Then, there is likely an analytics/ BI tool attached, all leading to Excel (which unfortunately acts as a de facto data platform for half the company).
Rather than a start-from-scratch approach (which is largely impossible), companies need to evaluate their data platform holistically and think incrementally. There are five considerations to think about here:
Current Platform Pain Points – Where are the challenges? What do people complain about daily? Focusing on these barriers helps identify the platform's modular components that could be added/ revised. This breaks down the immense task of platform migration/ development into bite-sized pieces that can be prioritised and addressed in an agile way
Organisational Structure & Operating Model – As mentioned above, you must align your platform's tech and data with your organisation's processes and structure. Without the symbiosis of the two sides, cracks will appear and won’t work as designed. Changing the org structure of the business is also extremely difficult and political, so consider that when thinking about any platform updates
Tooling Interoperability and Platform Orchestration – A critical success factor for each platform philosophy will always be ensuring the tools work with one another: (a) Benchmark from what already exists, (b) Understand what legacy tools can’t be replaced, (c) Figure out how the old and the new can work together, and (d) Consider orchestration tools (not just job orchestration, but platform orchestration tools like Orchestra) and processes to automate how technology works together in the platform
Cost to Build, Buy and Implement – Companies prefer building over buying. However, resource limitations and data salaries might make this choice more expensive than buying tooling add-ons. How implementation is executed also must be considered, as third-party expertise is often required, and timelines can run longer than initial estimates
Change Management – Getting buy-in, training stakeholders, and ensuring leadership support are vital to any platform adjustment. A lack of change management is a glaring issue for most companies when they buy new tools or modify their platform. Think holistically, keep the strategy/ goals in mind and make sure stakeholders are part of the process

What is the best Data Platform Philosophy then?
The answer is the two words everybody hates: “It Depends.”
You will likely take some sort of hybrid approach. This approach is more practical and less dogmatic because it is designed to flex to an organisation’s needs. But the most important thing when choosing a platform philosophy/ design is to remember why you have the platform in the first place—it should make sense of data.
Within that sentence are five benefits I outlined when explaining a Data Platform in my last article. When choosing your platform approach, consider these:
Empower Business Users – Making data an enabler for business stakeholders to make better decisions
Break Down Silos –A Data Platform should consolidate the data to provide a more holistic view of operations and decision-making
Ensure Consistency – Build a ‘single source of truth’ repository and ensure that data adheres to the same quality and security standards to create trust
Support Growth – Accommodate the growth and increased complexity of an organisation’s data, especially as the organisation scales
Compliance Adherence – Stay compliant with increasing personal data and security regulations or standards that impact business operations
Below, I have created a spider graph against all five considerations. This is not scientific but gives you an idea of how the pros and cons of each platform approach provide the benefits of a data platform.

As I said in last week’s article, a data platform is not a tool, technology or even a tech stack. It is an approach that aims to make sense of data. To do t his correctly for your organisation, it needs to be approached holistically, keeping the business goals, organisational structure, and underlying processes in mind. It will also never be perfect; greenfield data platform builds rarely exist, so consider the change management and planning required to make any adjustments successful.
Next week, we will finally move off the technology topic that has consumed this past month of The Data Ecosystem and move to Data Engineering. Specifically, what is data engineering, why is it such a hot topic, and what is wrong with the domain right now? I will never explain the topic (and its technical detail) as well as Zach Wilson, Joe Reis or Ben Rogojan (aka the Seattle Data Guy), but I want to approach it from a different angle. Trust me, it will be interesting and worth the read! So tune in next week and have a great Sunday all!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). See you amazing folks next week!
Nice read! Just curious, how would you apply these taxonomies to a very small startup with a nonexistent data team or a team of one engineer?
I’m wondering mostly about architectural and tech stack decisions that can be made at an early stage to enable flexibility in either staying centralized or moving towards hub and spoke with company growth. This could be a separate topic. 🙂
"The Data Fabric platform philosophy is confusing"...Finally, someone's had the guts - and nous - to say this publicly!
Thanks for another great article, Dylan, that clarifies these approaches to operating a data platform.