

Issue #60 – The Context Moat AI Needs
What a context layer actually is and why it is important in today's AI world

This issue is published in partnership with Kaelio, the team behind ktx, the open-source (Apache 2.0) context layer this article walks through. The framing, the opinions, and the consulting scars are mine. Kaelio’s team gave me the technical grounding on how context infrastructure is being built today.
Read Time: 15 minutes
AI is here, whether you like it or not.
And while it seems like everybody is absolutely smashing it with their new AI agents or tools, well, they aren’t.
There are lots of reasons for this, many of which I’ve written about:
Rushed implementation
Lack of training
Poor change management
No governance or guardrails
Choosing technology over processes and people
But honestly, the main thing holding back AI progress in most organizations is that their Artificial Intelligence isn’t actually intelligent.
Why? From my perspective, it comes down to a lack of context.

AI is built on heaps of data, and all that data creates a generalized sense of noise, even in the best of models. It’s like creating the smartest being ever, who knows a lot about everything but not much about one specific thing.
It’s that one specific thing, that context, that is really the driving force of AI quality in your organization.
So, building on last week’s reframing of AI strategy as a two track strategic implementation process, we’re going to tackle the next crucial concept you need to know in the Data & AI Ecosystem—the Context Layer.
The Growing Issue of Data & Context Fragmentation in an AI World
Every conversation I’ve had with Data Leaders starts with one common problem: the data is siloed and fragmented throughout the organization, and there is no consistent definition of KPIs or standards.
Okay, that’s two problems. But you get the gist…
Even as companies have invested millions in the ‘modern data stack’, data and knowledge have remained fragmented across dbt models, BI semantic layers, dashboards, Notion pages, Slack threads, and (the biggest culprit) in the heads of senior analysts and business stakeholders. Unless you did things really well, very little of those sources talk to each other. And—in this new day and age of AI implementation—almost none of it talks to the AI tools your organization has just plugged in, at least in a cohesive way.
Even though people seem to think Claude Code, Cursor, or GPT Codex are magic, the truth is this: MCP connectors, plug-ins, and agents don’t solve fragmentation. They expose it.
The pushback I get on this is usually: “Sure, but we’ve spent the last three years unifying everything into Snowflake / BigQuery / Databricks. The data is in one place. Just point the agent at the warehouse.”
If only it were that easy. A unified warehouse solves physical fragmentation, but it doesn’t solve semantic fragmentation. The agent still doesn’t know which of your six revenue columns is the one finance actually reports against. It doesn’t know which joins are safe and which one quietly double-counts orders when a customer has two addresses. It doesn’t know that “active customer” means something different to marketing than to the CFO. The warehouse tells the agent what tables exist. It doesn’t tell the agent what to trust.

In reality, the schema is a starting point, not a contract. The context layer is the contract.
Whether the agent is pointed at five disconnected sources or one unified warehouse, the outcome is the same: confident answers without the right context. And from my perspective, that is worse than no answer at all because the user trusts it.
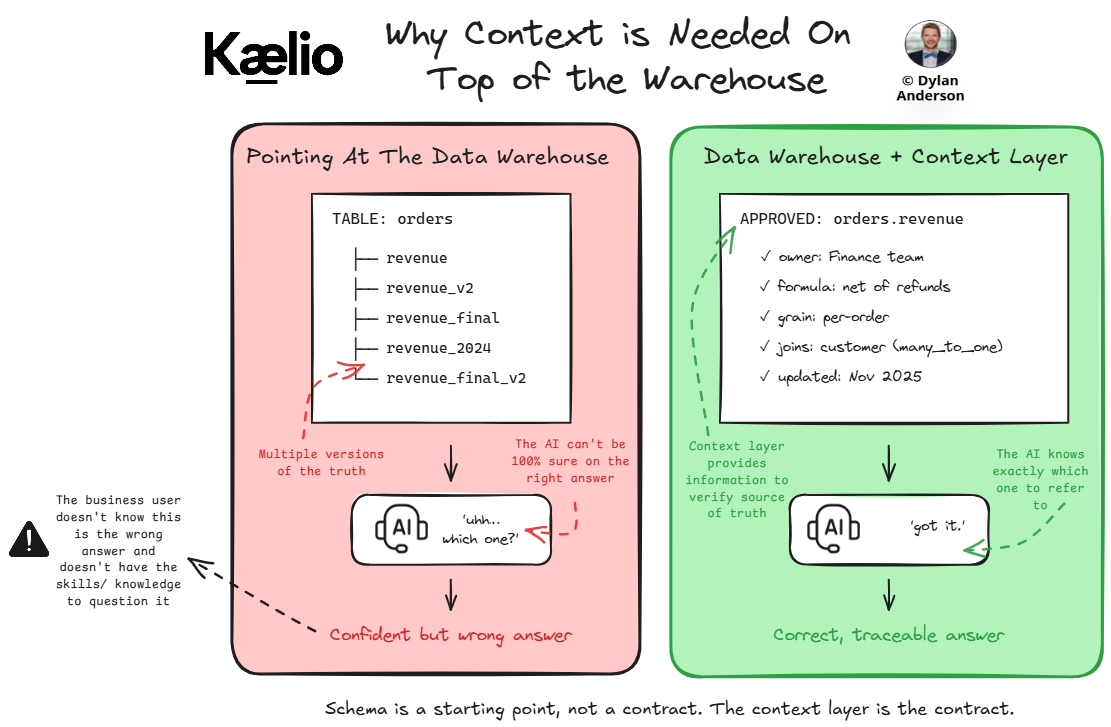
These users, by the way, are no longer just data analysts, but senior executives or leaders. Embedded AI means everybody can interact with the data and get a quick, confident response. The non-data business user likely assumes that the underlying pipes are connected and that the data is high quality. However, the more likely result is that context is out of date, partial, or not fit for purpose, and now it’s directly wired into business decisions without ensuring its accuracy.
The reality is this: siloed data and knowledge are what’s holding AI back across most organizations.
Not model quality. Not compute. Context. You may be more productive, but is it productivity if the outputs of your work aren’t contextually correct? And the cost of getting it wrong is starting to show up in output accuracy and quality failures.
The category emerging to fix this is the Context Layer. And while most of the early tooling is closed-source or bolted onto existing BI products, there’s a credible open-source option called ktx that I’ll dig into later in this piece.
From AI Strategy to Contextual AI
I recently met with the CEO of a mid-market CPG company. He’d been reading everything he could about AI and wanted to know how to implement it strategically. His first question?
“What model should I use?”
We’ve spoken about how tooling is not a strategy, especially for AI. Actually, I think that point has been made over and over again for the past 30 years. Nonetheless, it’s the question every executive still asks.
And you just can’t avoid it. Every C-suite or executive wants a tool or solution that provides immediate benefit. That is why they home in on the technology angle.
So what is the middle ground? Well, as I wrote about last week, it is shifting from purely strategic thinking about AI to a mindset of AI strategic implementation, where you actively embed AI in parallel to the strategic discussions. In fact, that is where I found the middle ground with that same CEO: I’m helping develop AI processes and workflows using a tool they already purchased, while outlining the longer-term operational AI roadmap. In this way, AI is not just a strategic document or a standalone tool bolted on; it finds the ideal middle ground, and you see value immediately.
But there is one more layer this approach requires to truly succeed—the business’s underlying context.
Context is king in today’s world. It is the KPIs, database schemas, metric definitions, and business rules.
The problem is that context has historically lived in individuals’ heads, requiring dozens of interviews, meetings, or workshops to extract the key information. And if we want to embed AI at scale, getting that kind of context in a usable state is difficult. Because no matter how hard we try, a single source of truth doesn’t exist. And it isn’t a case of plugging your AI into your database and calling it a day.
Instead, you need to start thinking about Contextual AI: building a layer of meaning from different sources, with the AI developing a baseline understanding that enables all AI workflows, while learning from it.
You can surmise the benefits of this for yourself, but the one thing I will say is that these benefits are not contained to your data team or Agentic AI users. Context helps everybody work smarter, and isn’t that what we want from AI? And if your context isn’t right, then doesn’t that eliminate the benefits of AI, causing distrust?
And this, my friends, is why everybody is currently obsessed with context layers, the tool that enables context at scale in your organization. You know I’m not a huge tool promoter, but this one isn’t hype. It’s the next foundational component companies need. And the one that determines whether AI delivers reliable value in your organization or quickly produces generalized answers (that may or may not be wrong).
What is a Context Layer?
The straight definition: a Context Layer is the trusted knowledge surface that sits between your data stack and the agents that query it. It captures what the business actually means by the data (e.g., the metrics, the joins, the definitions, the caveats) and serves that meaning to any AI tool or employee that asks.
With everything moving towards organizations using agents (and it is), there needs to be a managed connection to ensure the agents pull the right information. Otherwise, you get a wild west of meaning (which I’m seeing in most organizations right now, rushing to implement AI without the right contextual architecture).

The idea of context layering is not new. Every organization likely has a number of tools helping facilitate this process like Confluence, Jira, Word documents, Notion, etc. However, these tools were built for humans, not for AI. And you can be damn sure that organizing and maintaining them has never been any organization’s strong suit.
Now software exists that helps bring these things together and surface the agreed/ official metrics, which joins are safe, and what the business means by terms like “active customer,” while showing where every definition came from. Without it, AI Agents will not reflect reality (and therefore, what is even the point of AI-enabled workflows).
So how does a Context Layer help with that? Well, there are three components to it:
The Semantic Layer (Structured knowledge): These are the tables, columns, joins, measures, dimensions, segments, validation rules, etc., all pulled together via reviewed YAML files to create the schema-level truth about what your data is. It serves as a unified business layer that helps standardize definitions and KPIs, compiling your intent into SQL to query for your request. Basically, your AI agent declares what (“show me revenue for new product X this month”), and the semantic layer defines how (which tables to join, how to aggregate the data, the specific syntax of the warehouse, and how to keep the data clean/high-quality). A lot of data teams already do this work manually in their BI tool, but it ends up trapped too far upstream to gain credibility across the organization or be reusable. A proper semantic layer pulls it out of the BI tool and into a governed model any tool can query, thereby increasing the accuracy of any data requests (via SQL or LLM queries).
The Wiki (Unstructured knowledge): This context layer component handles the prose; organizing mass amounts of unstructured data held in an organization to define business terms, metrics, reporting policies, pull together dashboard notes, provide team-specific context, etc. These are stored as Markdown pages that an agent can search and follow references through (and individuals can access and verify). Behind the scenes, retrieval uses a hybrid pipeline (keyword search + semantic embeddings + a term-overlap fallback) so synonyms, paraphrases, and unfamiliar wording all surface the right page. For companies on Notion, Slack, or anything with onboarding docs (so… every company), this is where the actual business reasoning gets captured and made queryable by agents (or employees via an AI chat interface). And it means this type of enterprise search for meaning doesn’t have to happen over and over again manually.
The Audit Trail (Provenance/ Lineage): To trust the context, you need to see where it came from. Provenance is the source of proof and evidence (e.g., raw source snapshots, search indexes, citations back to the original source). The strongest pattern I’ve seen for this is to weave provenance through the other two components rather than maintain it as a separate document. With your AI interface, you can ask it, “where did this number actually come from?” and get an answer, whether that is a citation from the data warehouse, metric definitions from the wiki or links to its primary source. As the ktx team puts it in their review guide: wiki pages cite evidence and don’t duplicate YAML. This is the design pattern to look for when you’re evaluating context infrastructure because it makes the audit trail real, reduces ongoing maintenance, and builds trust in AI outputs, where hallucinations and accuracy are common realities.
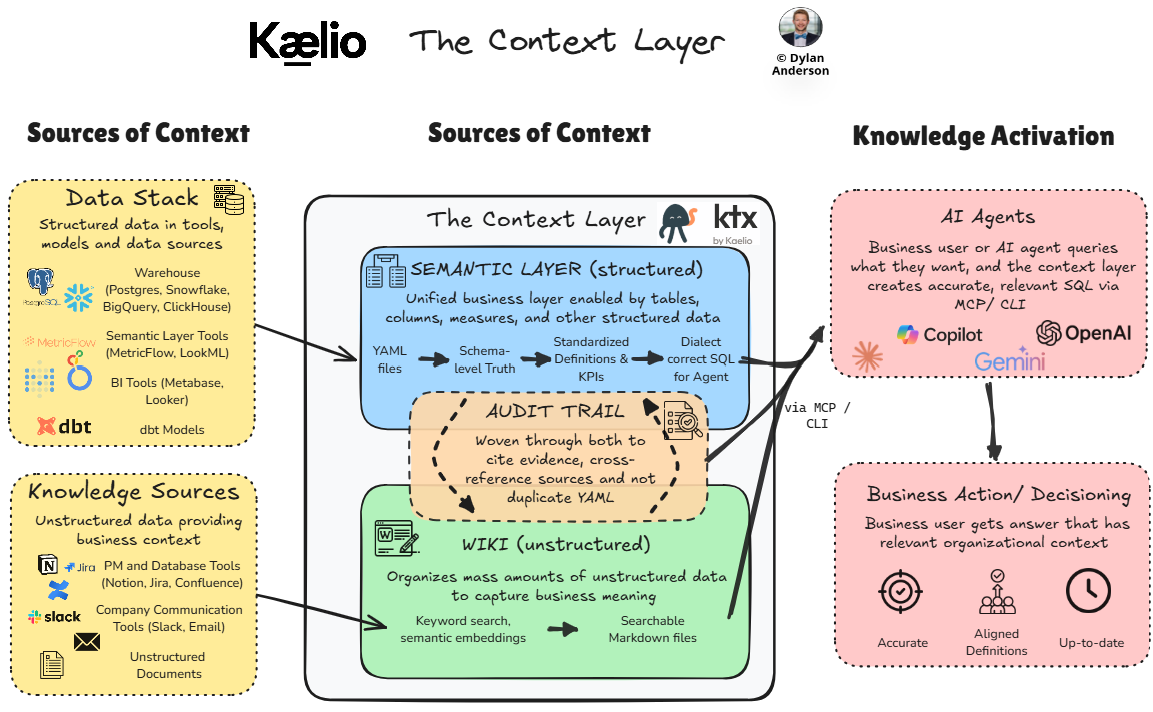
Now, each of these things has been around for a while, but bringing them together for Agentic AI is where the real value lies. Think about it: business stakeholders are actively querying their Claude, ChatGPT, or Copilot, and those tools are running Python or SQL engines to pull information from the main database.
Without a context layer, the AI Agent may be querying the numbers with the wrong definition. Or use the company Notion to find context, but not really understand how to query the warehouse correctly.
A properly built-out Context Layer combines these things in exactly the way that AI should work:
VP of Sales wants to understand whether the team has hit sales targets of a new product for the month
They ask their AI Agent to pull the data
The semantic layer turns that intent from the prompt into SQL
The wiki ensures that the definitions are correct and determines the implications of the numbers, using the AI Tool to provide any additional insights and implications
The provenance provides the audit trail to the data and definition so the VP can verify those numbers
The VP feels confident in their numbers (all in the span of minutes instead of hours or days)
So this isn’t about your new AI model being better or faster; it is about adding context to make it smarter and more impactful based on your own business context.
And without all three components, you only have partial context. And partial context produces partial accuracy, which doesn’t cut it in today’s AI environment.
The Path to Contextual AI
This is still very much an evolving space and most companies aren’t sure where to go with their AI tooling or their context layer. However, I would say that this uncertainty shouldn’t cause companies to pause investing in a Context Layer. The opposite really; they need to set it up before it is too late and there is so much legacy AI debt that undoing that old context becomes impossible.
I hate vendor lock-in, and this is a space where vendor lock-in can be so dangerous (because you are connecting to so much data and tools).
So it worked perfectly that Kaelio was happy to partner with me on this article. After realizing where the AI world was going, the team at Kaelio built and open-sourced ktx, a context layer purpose-built for AI agents. It’s free, Apache 2.0, and you install it with one command, allowing you to instantly connect to your structured database (Postgres, Snowflake, BigQuery, MySQL, and others), dbt models, semantic layer tools (MetricFlow, LookML), and unstructured knowledge from Notion.
With most companies still wading into the Agentic AI world, many aren’t ready to sign up for an expensive semantic or context layer tool, making open source the perfect solution. And as demonstrated above, you need a tracked context repo that your AI agents can query through via MCP or CLI to ensure the accuracy and relevancy of the outputs, which is what ktx gives you out of the box, for free.
Why Context Is the New Moat (and What Good Looks Like)
People have been talking a lot about moats recently (the sustainable competitive advantage that protects an AI business from competitors).
Well, I want to finish this article by stating my perspective: Context is your company’s moat! But to do that, you need to embed it into how your AI-enabled business operates.
This comes from three trends I’m seeing in AI:
Foundational model costs are going to rise, not fall: For OpenAI and Anthropic, we are starting to see price increases and usage caps. Not to mention, as more people within the organization use AI, total spend will rise with usage. And if those queries are running without context, the agent burns far more tokens on database lookups, then retries, second-guesses, or produces wrong answers that get rerun. The more context an agent has up front, the fewer tokens it wastes and the more often the first answer is correct.
People are becoming reliant on AI: I’ve seen a lot of senior leadership teams say they are being more productive, but are relying on handing off work to AI. This has resulted in a lot of sub-par outputs. This isn’t sustainable and businesses will begin to take notice. But they won’t want to switch back to manual work, they will want the company’s AI Agents to be smarter and produce higher quality outputs. Hence, the need for a context layer. This is where AI work is heading whether companies know it or not (and most don’t yet).
Agents are getting more capable, increasing their responsibility: This kind of builds off the previous one, but takes a different angle. Companies are starting to throw real money into enterprise plans for Agentic AI. And now that agents can reason, write proficiently, execute code, call tools, and chain together complex workflows, the expectations are increasing. When they don’t perform up to snuff, the first thing leadership will look to will be another tool (unfortunately it won’t think about training or recreating processes). That tool is going to be a context layer, because making context implicit in how these agents work is going to be the fastest way to value.
So my perspective is that if companies want to embed AI and become genuinely AI-native, their tech investment (beyond the processes and the people) should shift from tokenmaxxing to contextmaxxing. That’s where the durable advantage lives, and where the next five years of analytics investment will go.

If we are heading this way, what does good look like? From what I’m seeing, the properties of strong context infrastructure are:
Unified integration across the stack – Pulls together everything from databases, transformation tools, semantic layers, and knowledge documents/ sources. This portability is crucial because most organizations have all of these data sources, but almost none of them speak to each other.
Version-controlled and local – Git-backed, so context evolves the way code does. By having pull requests for metric definitions or audit trails on changes you have embedded context governance for AI. You think context is a hot topic, don’t get me started on governance… Luckily, version control can help fast track the checks and balances teams need.
Agent-agnostic – People use multiple models, so exposing your context layer via MCP and CLI allows any agent to plug in. Don’t make AI another Microsoft Office vendor lock-in strategy. And you don’t want to rebuild your context every time the agent landscape shifts (the AI version of a data migration).
Open source – I believe context infrastructure is something you need to test and play with to determine whether it works for you. I mean, if the tooling is a black box, how can you know it is working well? This is exactly why ktx is open-source. With AI advancing so quickly, locking yourself into a multi-year vendor contract in an emerging area like context layers isn’t necessarily the right option. This domain will only improve, and an actively maintained, open-source tool like ktx will probably lead the way.
Structured and unstructured together – When setting this up, you have to think beyond the semantic layer (there is a reason they never took off on their own). The wiki layer—unstructured data—is where the business reasoning lives, so make sure this is embedded to get the accuracy you need.
Governed and updated context – Integrated with clear, deterministic guardrails that keep context from going stale. A context layer is only useful if it’s true. When it starts drifting from how the business actually operates, the downstream AI Agents get worse (even though they are just as confident). Any context layer tool should help maintain that, else it will go the way of the Data Catalogue…
An example of how this should be built is Gladia, an audio AI infrastructure company. Being AI-native they wanted to do BI in a more direct way, but were running into accuracy problems. When they pointed agents directly at the warehouse (BigQuery) to answer business questions, the outputs were unreliable—the same semantic-fragmentation failure that so many companies experience in production. The primary issue was that agents had no idea which metrics were trustworthy, which joins were valid, or what the business actually meant by any of it. The ktx context layer helped provide them with a more governed, semantically aware path, with the agent querying through the context layer rather than the raw warehouse.
Now you may be skeptical that I’m trying to sell you something here, but in all reality, the only thing I want to sell to you is that Contextual AI is the future. I now use ktx on my own machine, and although I’m not using a ton of data, my life is a lot easier. Trust me, I do consulting, book writing, newsletter writing, LinkedIn posting, etc., so organizing my context and aligning it with my Claude Code are essential for me to be productive and avoid burnout.
In the end, you shouldn’t solve AI hallucinations or agent accuracy with more prompts or tokenmaxxing. Instead, build the right contextual foundation for the future, on top of all the valuable data you already have. And if you run into an “AI debt” problem in a couple of years, don’t say I didn’t warn you!
A note on this partnership: I worked with the team at Kaelio on this article. They built ktx, the open-source context layer this article references throughout. It’s worth a serious look if you’re thinking about how to operationalize context infrastructure inside your stack. They want you to know more about the topic and helped me sanity-check the technical claims. Seriously, check them out. It is a great product and team!
Thanks for the read! Comment below and share the newsletter if you think it’s relevant! Feel free to also follow me on Substack, LinkedIn, and Medium, or reach out if you are looking for some top-notch freelance consulting input! See you amazing folks next week!