

Issue #41 – The Production Process for Machine Learning Models
Clearly articulating what it means to go from use case to ML model to productionised solution

Read time: 15 minutes
People like to think they are data scientists when they go on Kaggle and complete the Titanic prediction competition.
Their model is well thought out.
It works flawlessly in your Jupyter notebook.
The metrics look great.
Your test data validates your approach.
So, obviously, that means they are ready to build some real-world ML models, right?

You know the answer to that…
Obviously, production and deployment are harder than local development.
So after covering the basics of AI and ML, the fundamentals, and the different types of ML models and AI solutions in previous articles, it's time to get into the weeds and understand what it takes to productionise an ML model.
Because let’s be realistic, even the most sophisticated algorithm is worthless if it never makes it into the hands of users or business processes.
Let’s dig into Part 5 of my ML & AI series (feel free to read any of the previous parts above if you’ve missed out)!
Brief Disclaimer About Productionising ML & AI
Before we get into the specifics, let's be honest about something...
Productionising ML models is far more complex than most people realise:
Real-world data is of varying quality
Your local machine is different to production infrastructure
The Python scripts/ algorithms will also run differently in production
To realise value, you must work with and get buy-in from people to use your model
I wanted to therefore bring you back to those four core components of ML & AI we discussed in our first article and revisit them through the lens of productionisation:
The Data: As the foundation of any ML/AI system, your production environment needs reliable data pipelines that ensure continuous, high-quality data flows. Sorting out what data you need, how accessible it is, how it is maintained and the specific quality it comes in is crucial to ensure the model performs well over time and the output is useful.
Tech Infrastructure: Moving beyond your local development environment requires infrastructure that can handle real-world loads. Production systems need scalable computing resources, properly configured deployment environments, monitoring capabilities, and potentially edge computing for specific use cases. Oh and you also have to make sure you don’t blow the whole cloud or compute budget running redundant scripts.
Algorithms: Testing and training algorithms on a machine is easy; packaging, containerising and optimising your algorithm for deployment is another story. This often means refactoring code for efficiency, ensuring proper versioning, and implementing error handling for unexpected inputs.
Human Expertise: The most overlooked aspect of productionisation is the cross-functional expertise required. Working with the right business stakeholders to craft the use case, data/ ML engineers to pipe in the data, data scientists to develop the algorithm, MLOps/ DevOps specialists to understand the deployment environment, and domain experts to get nuances about the tech are all crucial inputs. Collaboration is key!


In addition to these four core components, there are a few other steps and challenges you have to face as a fledgling young Data Scientist. If you don’t keep these things in mind, your attempts will fail!
Stakeholder Buy-in: Convincing business leaders to invest in an ML system requires you to demonstrate clear ROI. What is the value it will create? What revenue will it generate, or what costs will it save? How does that compare with the required investment? Given deployment timelines and unpredictable outcomes, this can be difficult, but it is incredibly necessary, nonetheless.
Use Case Definition: Don’t build for the sake of building. You need a well-defined use case that has been scoped out with relevant business and technical stakeholders. If your ML model doesn’t solve real business problems, then it won’t be used. Or if it’s not technically feasible at scale, then it will be impossible to productionise.
Cross-Team Collaboration: A Data Scientist may build the model script, but engineering teams deploy them, and product/ business teams use them. Collaboration, communication and well-defined handoffs/ documentation is crucial. Otherwise there may be undue friction between teams and a broken chain equals a broken model.
Unrealistic Expectations: You need to always tamper expectations. Once you hype up the tool to get investment, leadership might expect quick deployment (especially after seeing promising prototype results). They do not (and will never) understand that productionisation typically takes 2-3 times longer than initial model development. Plan in phases, create timelines and be realistic with what is required!
These are my disclaimers about productionisation—you need to keep these complexities in mind!
Now let’s move on to the production process because this is where the rubber hits the road!
The Process of Productionising ML & AI
Don’t expect the world from this section; these next few paragraphs aren’t going to teach you to become a Data Scientist or AI expert.
But what it will do, is make sense of the process to get from raw data to a Machine Learning product (let’s say a product recommender engine).
So where do we begin?
While many view machine learning as simply training models with Python code, the reality is far more complex and structured.
The ML development process is a systematic journey from business problem to deployed solution, requiring careful consideration at each stage to ensure technical delivery leads to business value.

This breaks down into four phases, with a number of steps in each:
1. Model Scoping & Data Foundations
This initial phase sets the foundation for success by defining clear objectives and ensuring data readiness. Without proper scoping and data preparation, even the most well-built models will fail to deliver value.
Problem Definition – The first step is to understand the problem. What are the business needs? How does that translate into a clear ML problem statement? With business stakeholders, work to define the objects, success metrics, KPIs, constraints and use cases. At this point, don’t even mention the word data. With a recommender engine, you might set your goals or metrics of what you are optimising for, while laying out the business constraints (e.g., don’t recommend this type of product).
Data Sourcing & Considerations – With the problem set out, then work to understand what data you have, where it comes from and what limitations might exist. Identify relevant internal and external data sources and understand their accessibility (or lack thereof) by mapping out their lineage. Another point is to determine data access permissions and regulatory requirements (like GDPR or CCPA) which might restrict how data can be used. For example, a recommender engine’s customer data would likely need to be anonymised.
Data Ingestion – Leveraging the existing data model and architecture (hopefully there is one), this step involves building reliable data pipelines to source and collect relevant data. I would recommend building a specific data model extract diagram or enterprise relationship diagram (ERD) about how that data comes together from the various systems/ sources. A recommender engine might need historical purchase data, product catalogues, customer behaviour data, and demographic information.
Data Preparation – Transforming the raw data into a clean, analysis-ready format. This is your standard data engineering/ETL builds (via those initial pipelines), addressing missing values, duplicates, unstandardized formats, and other data quality issues. For supervised learning models, this phase would also require data labelling and annotation processes, which can be time-consuming but necessary to improve your model's ability to learn correctly. Remember: garbage in, garbage out.
Exploratory Data Analysis (EDA) – Before jumping into ML modelling, investigate your prepared data to understand patterns, relationships, and potential issues. Hypotheses change, so the EDA may identify trends or new ideas that can be discussed with stakeholders before jumping into the full model development.
2. Model Development
With the foundations set, this phase is where you actually build a functioning machine learning model based on your prepared data. It is not just about writing an ML script in Python, as you have to think about how feature creation, algorithm selection, and training all factor into reproducibility and performance if you aim to productionise the model.
Feature Engineering – After understanding the approximate direction your model should be built, you need to design ‘features’. This involves converting raw data into meaningful inputs that ML models can use. This may include creating new variables that aren’t in the initial data set. It is a crucial step between data preparation and model training to ensure the model is based on the right metrics. In recommender systems, this might involve creating user interaction matrices, computing engagement metrics, or generating features from historical behaviour. This data likely doesn’t come directly from the source systems, so business logic and stats/ math would be needed to enhance it.
Model Selection – Choosing the algorithmic approach that best fits your problem, data, and requirements. Are you going to do regression, KNN, random forest, Support Vector Machines, etc.? Test out a few model options and evaluate the different architectures against your constraints and objectives. A recommendation system specifically would often use some sort of collaborative and content-based filtering to identify preferences and match it to content. This may use a combination of clustering to segment customers and regression to match variables/ attributes of the product (of course you may take other approaches).
Baseline Model Development – Before investing resources (and time) in complex model architectures, establish simple baseline models that represent the minimum viable prediction approach. These serve as performance benchmarks against which more sophisticated models can be measured. For a recommender system, this might be as straightforward as "recommend the most popular products". Baselines help quantify the actual value-add of more complex algorithms, prevent over-engineering, and provide fallback options if advanced models fail in production. It also gives you a step to demonstrate business value to stakeholders and set realistic performance expectations.
Version Control – While traditional software requires the registration of different software versions, machine learning models need a central repository for managing and tracking both involved code and data. You can do this in a centralised or distributed way. Centralised means there is one repository from one centralised server, which devs must ‘checkout’ to make updates. Distributed is more common, with branched sub-repositories connecting to one centralised repository. This is basically how git works. Overall, ML requires versioning of code, data and experiments to ensure reproducibility, identify optimal versions, and ensure any work is backed up.
Model Training – Okay, now you’ve built your ideal model; now it is time to execute the actual learning process. After splitting the data up into the training and testing subsets, you run your chosen algorithm to learn patterns from the training set. To do proper training, you need to set up training pipelines, implement cross-validation strategies, and constantly tweak the script to optimise model hyperparameters (this takes many iterations and is why version control is so essential). A recommender system would use training data to match user preferences and item relationships, basing it on the outcome of whether a person purchased or engaged with the recommended product.

3. Model Deployment
All of the above elements can be done locally on your computer. But with the model developed and trained, it is now about bringing the model to production so it can deliver value throughout the organisation. This isn’t just about spinning up an instance and launching it via a containerised environment in an application. Instead, it requires careful planning and robust infrastructure to ensure reliable, scalable performance.
Model Evaluation & Validation – We explained initial model training in the previous phase as the model is developed, but to be input into an ML system, more comprehensive testing frameworks are required to validate model performance before deployment. This is where you factor in things like unit testing, integration testing for pipelines, performance testing, model comparison, and CI/CD testing. You also have to think about setting up metrics, testing procedures, and monitoring systems to ensure the model meets both technical and business requirements.
Model Serialisation & Packaging – Before a model can be deployed, it must be properly serialized into a format that allows it to be saved, loaded, and executed in a production environment. This involves selecting appropriate serialization formats (like ONNX, pickle, TensorFlow SavedModel, or PyTorch TorchScript) based on compatibility requirements and performance needs. The serialized model must be packaged with its dependencies to ensure consistent behaviour across environments. For recommender engines, this might include not just the model itself but also preprocessing components and feature transformation logic.
Resource Planning – As you build the model, you need to factor in the data platform, and existing infrastructure necessary to serve your model effectively. Backend infrastructure deserves a whole article on its own, but for now just remember to important to consider computational requirements, scaling strategies, and how the deployment is managed. To stand up a recommendation engine, you would need to plan the computation/ technology for both batch processing of user histories and real-time serving of recommendations.
Deployment Architecture Planning – The technology/ tooling infrastructure isn't the only architectural element you need to factor in. Considerations around the deployment environment to encourage reproducibility and how that links up to the data flows, scaling infrastructure for varying loads, and APIs for model endpoints/connections are critical. This often involves containerization strategies using Docker and orchestration with Kubernetes for managing deployments across environments. For example, what is a model serving strategy (dedicated servers vs. embedded models) that optimize both performance and maintainability.

Don’t be a naive junior DS, you need to build with deployment in mind! Business Integration/ Model Deployment – Here, you integrate your model into existing business systems and processes. This involves setting up APIs, connecting to business applications, and ensuring smooth data flow. For recommender systems, this means integrating with e-commerce platforms, email systems, or other customer-facing applications, often through APIs that handle both request throttling and proper error handling.
Model Registry – While traditional software requires the registration of different software versions, machine learning models need a central repository for managing and tracking both involved code and data. Unlike simple serialization, which prepares individual models for deployment, the registry maintains a comprehensive inventory of all model versions, their associated metadata (training datasets, hyperparameters, performance metrics), deployment history, and approval status. This creates an audit trail essential for governance, compliance, and troubleshooting. For recommender systems where multiple models might target different product categories or user segments, the registry becomes crucial for managing the growing model ecosystem and ensuring proper version control during rollouts and rollbacks.

4. Maintenance
This final phase ensures your deployed model continues to perform effectively over time, adapting to changing data patterns and business needs.
Feedback Loops & Continuous Learning – One of the most powerful aspects of deployed ML systems is their ability to generate new training data through user interactions. Establishing systematic feedback loops allows you to capture how users respond to model outputs (like whether they click on or purchase recommended products), which becomes an invaluable training signal for future model iterations. This creates a virtuous cycle where model performance improves over time as it learns from real-world usage patterns.
Performance Tracking – This step involves continuous evaluation of your model's business impact and operational costs. It goes beyond technical metrics to track actual business value creation, like increased revenue or improved customer engagement, while monitoring infrastructure expenses, compute utilization, and other operational costs. For recommenders, this means balancing metrics like recommendation click-through and conversion rates against the infrastructure costs of generating those recommendations. Establishing cost-benefit frameworks helps identify when more complex models justify their higher computational requirements and when simpler approaches might deliver better ROI.
Model Monitoring & ML System Observability – Once deployed, models require continuous surveillance to ensure they remain effective in a changing environment. This involves end-to-end monitoring of the entire ML system to detect data drift (when production data differs from training data), concept drift (when the relationship between inputs and outputs changes), and model performance degradation. Proper observability requires having appropriate logging and metrics collection at every step to understand system health, with alerting thresholds to trigger when interventions are needed. This proactive approach helps identify issues before they significantly impact business outcomes and provides valuable diagnostic information.
When I started writing the above process, it was supposed to be short and concise, but as you can see, it grew legs.
The same will happen with building and deploying your ML application.
There is so much that needs to be thought of, and we haven’t even touched on the user adoption and change management required to properly use it!
All in all, it’s a lengthy and complex process, and the above just scratches the surface. If you want to get a deeper understanding on some of these elements I suggest reading Decoding ML and Swirl AI.
Wait, What About MLOps?
So, throughout all of that, I didn’t mention MLOps.
Well MLOps spans the entire process—from version control to deployment architecture to monitoring.
This term builds on DevOps (from traditional software development) and combines machine learning, data engineering, and software engineering to streamline the entire model lifecycle. It's not a single phase or step but rather the operational framework that enables all four phases outlined above to work together seamlessly.
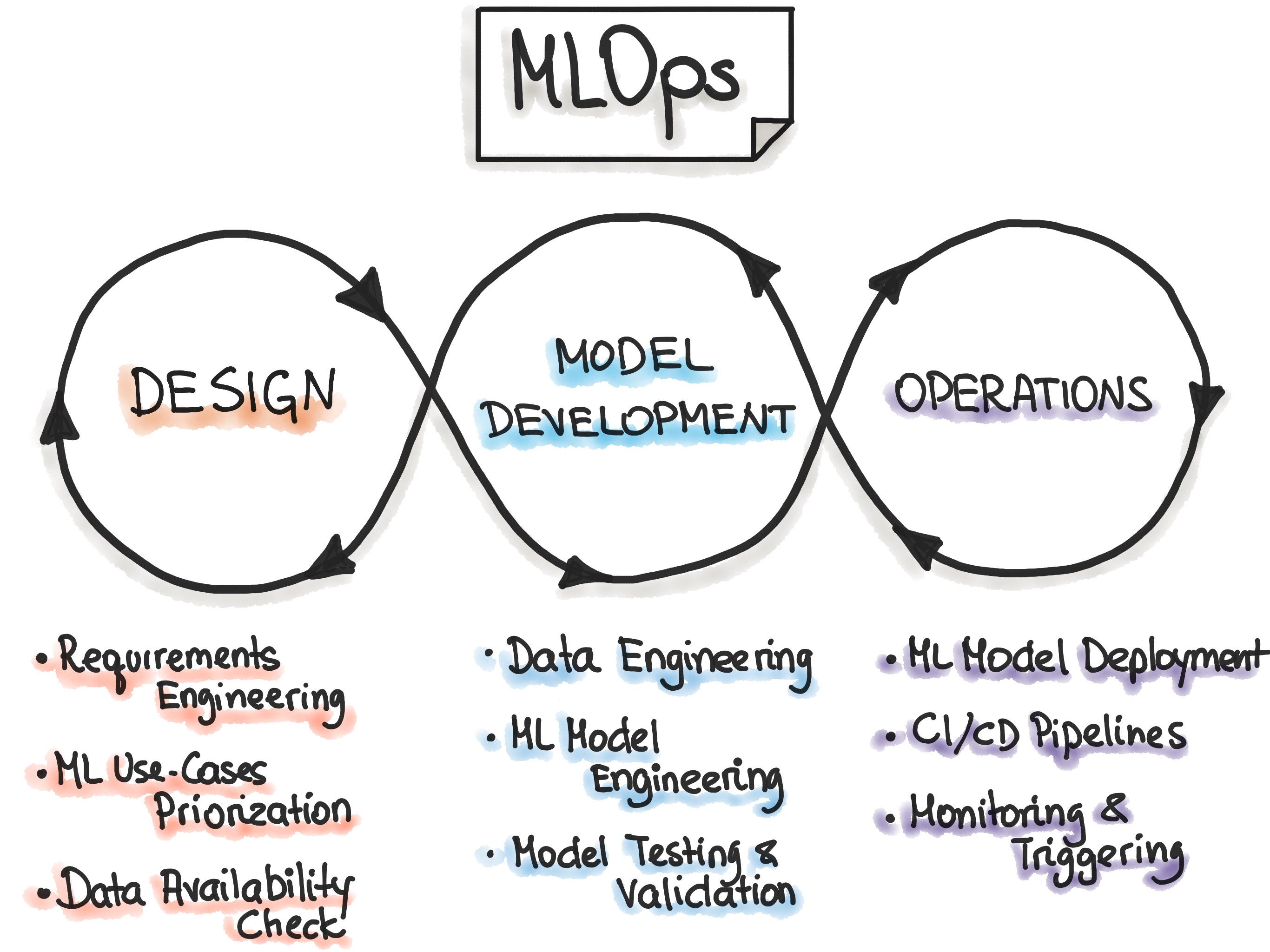
There are five Key MLOps capabilities that span across our four phases:
Automation: Reducing manual steps in model training, testing, and deployment
Reproducibility: Ensuring consistent results across different environments
Versioning: Tracking changes to code, data, and models
Collaboration: Enabling data scientists, engineers, and business stakeholders to work together effectively
Governance: Maintaining oversight and control of models throughout their lifecycle
While it's possible to productionise ML models without a formal MLOps practice, organisations that invest in MLOps typically see faster deployment cycles, more reliable model performance, and significantly reduced maintenance costs.
As you build out your productionisation capabilities, consider MLOps not as an additional task but as the operational mindset that should inform every step of the process. I plan to do a more thorough article on this in the future, because it definitely deserves a full debrief!
Wrapping Up the Productionisation Journey
So there you have it—the complex journey from idea to prototype to production-ready ML system.
While we've covered a lot of ground, the key takeaway is simple: productionising ML requires just as much focus and investment as building the initial model. In fact, it often demands more.

As you may infer, Machine Learning models don't exist in isolation—they're deeply interconnected with every domain in the Data Ecosystem. From data quality to infrastructure to engineering to architecture, successful ML deployment depends on the health of your entire data environment.
As AI continues to evolve and become more widespread, the organisations that understand what is required to productionise ML models will be the ones that extract real business value from their data investments. They'll move beyond the hype cycle to build systems that deliver tangible improvements to operations, customer experiences, and bottom lines.
But they have to keep in mind the greater Data Ecosystem!
Therefore next week, we will conclude our ML & AI series by explaining the Data Ecosystem considerations you have to make to realise the value from Machine Learning and AI. Nothing is localised in the Data Ecosystem and the connections an ML product has to other data domains means Data Scientists have to think with a more holistic perspective. Until then, have a great week and thanks for the read!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). And if you are interested in consulting, please do reach out. See you amazing folks next week!