

Issue #39 – Types of Machine Learning Models
What are the different types of Machine Learning? How can you use it?

Read time: 12 minutes
Since machine learning became a thing, people have wanted to do it
Remember the data scientist was the sexiest job in the 21st century?

Twelve years since that proclamation, most companies I work with haven’t done much ML at all. Or they’ve done some ML and didn’t realise they used an ML algorithm!
This is the biggest problem with the data science, Machine Learning and AI domains! There is:
A significant lack of topic understanding
…coupled with incredible hype from ‘experts’
…who don’t care to learn the nuances of the subject
…leading to unrealistic expectations and a lack of quality results
In the last two articles, we spent some time building the baseline of what ML & AI is and the foundations of what it is built on.


For the next two articles, it is time to shed some light on what people are actually building when it comes to Machine Learning and AI.
So let’s start with ML, because without ML you can’t get AI. So roll up your sleeves and let’s dig in!
Understanding Machine Learning Model Categories
Machine Learning as a domain seems daunting.
You hear all the rhetoric, fluff, and exaggerated claims, and it is hard to grasp what happens when somebody builds an ML model.
Let’s pull back the curtain here and simplify the best we can.
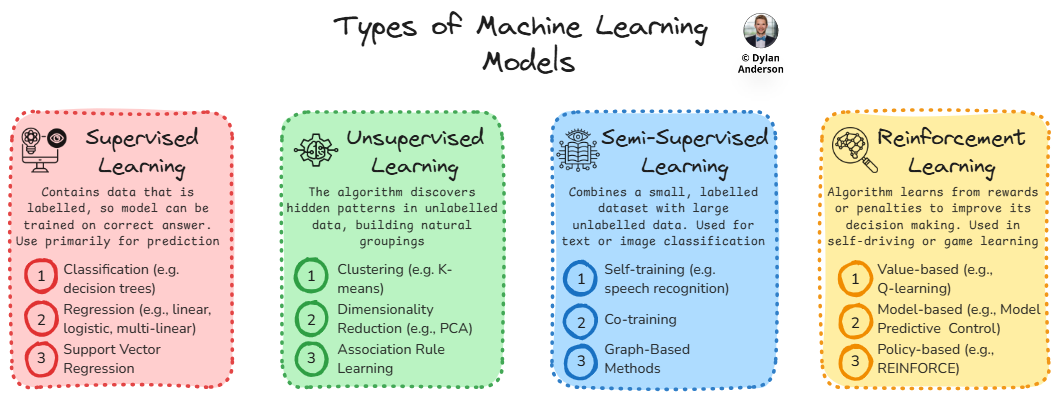
Essentially, there are four key categories of Machine Learning:
Supervised Learning
Unsupervised Learning
Semi-supervised Learning
Reinforcement Learning
Supervised Learning
Supervised Learning is just that; it’s supervised. This means the data is labelled by humans, ensuring a correct answer for the data to be trained on.
With correct outputs located within the whole dataset, the data is split into two—the training and testing data. The algorithm (or model) is built using the training data, which helps the influence each input variable has on the output variable (or the answer). The testing data is then used to assess the model’s effectiveness at getting the right answer without knowing the output.
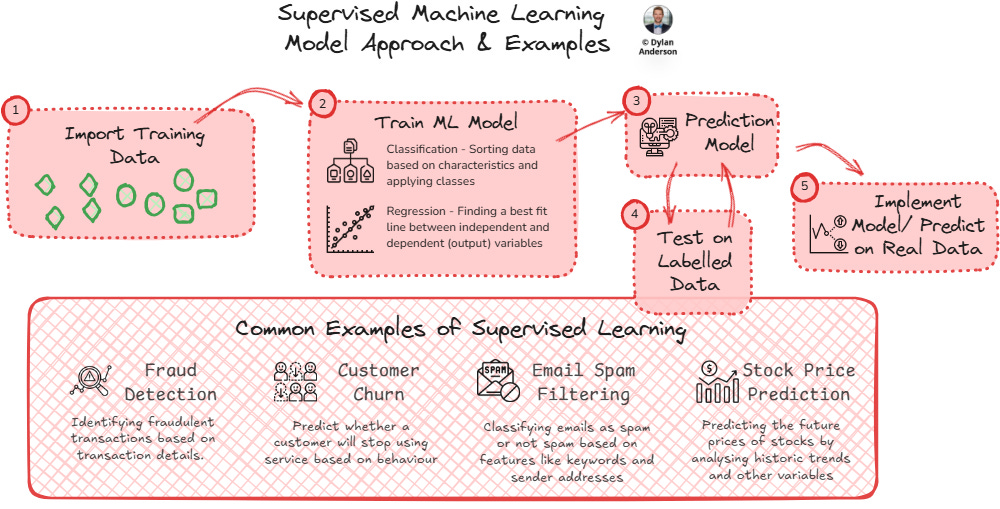
The primary use case for supervised learning is prediction (e.g., email spam detection, loan default detection, medical diagnosis, image classification, etc.). The two main types of supervised learning are classification and regression.
Classification focuses on sorting data points into predefined groups based on their characteristics. These classes are then applied to the testing data set, classifying that data based on the learned characteristics (and determining how accurate the classification is). Decision trees are a popular form of classification, predicting a decision based on how the characteristics break down.
Regression uses variables to find the best-fit line between the data, allowing individuals to predict continuous variables. The most popular forms of regression are linear (on input/ predictor variable trying to determine one output variable, with a straight line fit determining the relationship between the two) and multi-linear (with multiple independent variables determining the output variable). Other forms of regression exist (e.g., logistic, multivariate, ridge, polynomial, etc.), but most default to linear regression, which is one of the most simple and common forms of predictive analytics yet incredibly powerful.
Support Vector Regression is also a popular form of Supervised ML that falls under classification and regression. It breaks down the data into two classes/ groups and finds an optimal line/ hyperplane between them, helping make optimal, accurate classification predictions.
Supervised learning is excellent for learning complex patterns and has improved predictive accuracy. However, improved accuracy is largely due to the dependency on human input to label the data, which can be costly and time-consuming. You also run the risk of over-fitting, making it harder to trust the results. Therefore, many ML projects cannot rely on supervised learning alone, given the unknown variables within most real-world data.
Unsupervised Learning
As you might surmise, Unsupervised Learning contains data without predefined outputs. The algorithm is relied upon to discover hidden patterns and structures within datasets by exploring and finding natural groupings.

The primary use case for unsupervised learning is pattern discovery and data exploration (e.g., customer segmentation, anomaly detection, recommendation systems). The two main types of unsupervised learning are clustering and dimensionality reduction:
Clustering groups similar data points together based on shared characteristics (similar to classification but without predefined categories). By identifying similarities/ differences between data points, you can find unseen trends in the datasets. This is particularly powerful in business contexts like market segmentation or identifying customer behaviour patterns. K-means clustering is one of the most popular approaches, partitioning data into a specified number of clusters based on similarity.
Dimensionality Reduction simplifies complex datasets by reducing the number of variables while preserving important patterns. Principal Component Analysis (PCA) is the most common technique, identifying vectorised principal components that can describe the dataset and allowing for the reduction of features and noise in the data.
Association Rule Learning discovers interesting relationships between variables in large datasets. A classic example is market basket analysis, where retailers analyse which products are frequently bought together, making recommendations based on those patterns.
Given that labelling data is time-consuming and difficult, unsupervised learning is incredibly helpful in uncovering patterns we might not even know how to look for. A lack of labelled "correct" answers can also prove challenging as it can be difficult to validate the results and ensure they're meaningful for your business context.
Semi-Supervised Learning
Semi-supervised learning takes both previous approaches and merges them together. By combining small, labelled datasets with large, unlabelled data, you get a bit more control and accuracy on what the output might be.
The reason for semi-supervised learning? Well, it is more common for real-world applications; most data isn’t labelled but you still need to make use of it!
Semi-supervised learning can be applied to a number of different ML approaches, it just requires including some labelled data to determine the correct answer. This understanding then feeds into large unlabelled datasets. Its primary use cases are also relatively common, like text classification, image classification or anomaly detection. Below, I’ve identified three methods of semi-supervised learning:
Self-training takes a small amount of labelled data, which is used to train an initial supervised model. Then, the partially trained model will be used to predict the unlabeled data. The most confident predictions (deemed pseudo-labels) are added back into the training set, gradually expanding the labelled dataset. Speech recognition and image classification are two common examples of this methodology.
Co-training methodology pulls from the same logic as self-training but uses multiple views or perspectives of the same data to improve learning. This allows for two sets of classifiers and pseudo-labels, which can be compared against one another to improve accuracy. For example, a video could be analysed using both visual and audio features, with each perspective helping to validate the other.
Graph-based methods create assignments for unlabelled data points by identifying connections between labelled data points based on similarity. The algorithm is graph-based as it uses the structure of a graph (nodes connected by edges), like the smoothness and cluster assumptions, to make predictions on what data should be labelled. This is also referred to as label propagation.
In addition to self- and co-training, you may see semi-supervised Generative Adversarial Networks (GANs), clustering, support vector machines, or deep learning models. Given you can add more accurate labelled data to unsupervised algorithms, the semi-supervised approach provides a middle ground for machine learning, reducing the cost and effort of labelling all data while still maintaining good predictive performance.
However, these algorithms must be monitored to ensure the model doesn't amplify its mistakes through self-training.
Reinforcement Learning
Reinforcement Learning fundamentally differs from previous approaches, as it focuses on learning through interaction with an environment.
Instead of being given the correct answers at the outset, the algorithm learns by receiving rewards or penalties for its actions, gradually improving its decision-making strategy. For example, it is rewarded when it makes the right action/ decision; when it makes the wrong one, it gets negative reward signals. This is a very similar concept to teaching a dog new tricks.

Reinforcement learning has a lot of well-known use cases. Consider game playing (like AlphaGo), self-driving cars (or autonomous systems in general), and robotics. Any approach to reinforcement learning requires four key components:
Agent – The subject of the process, performing different actions assigned to it
Environment – The situation or environment that the agent is placed in
Actions – What the agent needs to do to reach the goal
Rewards – The feedback (positive or negative) the agent receives after performing an action, required to help train the agent
There are three popular algorithms within reinforcement learning:
Value-based Reinforcement Learning trains itself to find the optimal value function to be in a given state. A popular version of this is Q-Learning, where the algorithm provides guidelines to the agent about what actions to take and the circumstances to win the reward. This is based on Q-tables (hence the name), which get updated after each action, allowing the agent to see which actions have the best form of ‘value’ (i.e., getting it to its goal faster)
Model-based Reinforcement Learning focuses on a model of the environment to simulate different actions and outcomes of the agent in the environment. This helps the agent plan its actions. This approach is not as popular, but the two approaches here are Model Predictive Control (using a learned or predefined model to predict the next few steps) and World Models (agent learns a compressed representation of the environment using deep neural networks).
Policy-based algorithms focus on updating the policy from which they learn. This means mapping the state to the probability of selecting actions rather than mapping it to the value. Examples include the REINFORCE algorithm, which updates the policy according to the gradient of expected rewards. This approach is more effective in environments with continuous actions.
Reinforcement learning has achieved impressive results in controlled environments. Still, it can be very challenging to implement in business contexts due to the need for extensive trial and error, which isn't always practical.
Overall, it provides a very interesting way to solve complex sequential decision-making problems, making it an increasingly important tool in the Machine Learning domain.
What About Deep Learning
Now you may be thinking: “But Dylan what about Deep Learning? You forgot about that one.”
Deep Learning is not a separate category but rather a subset of each of these four methods. It uses specific algorithmic structures called neural networks (similar to the networks between areas of our brain). These neural networks automate more complex tasks that require human intelligence by processing data through multiple layers of interconnected nodes (i.e., neurons), with each layer learning increasingly abstract features of the data. The algorithm ascribes weights to these nodes, training it to get a more accurate result while looking to reduce bias and errors.
What makes deep learning special is its ability to automatically learn hierarchical representations from raw data without extensive feature engineering.
For example, in image recognition, early layers might learn to detect simple edges, while deeper layers combine these to recognize complex objects like faces or cars.
The ability to break the problem-solving algorithm into multiple layers increases its ability to improve accuracy and have specific nodes focus on unique elements. Given the complexity inherent in computer vision, natural language processing (NLP), and speech recognition, this approach has exponentially evolved fields like these.
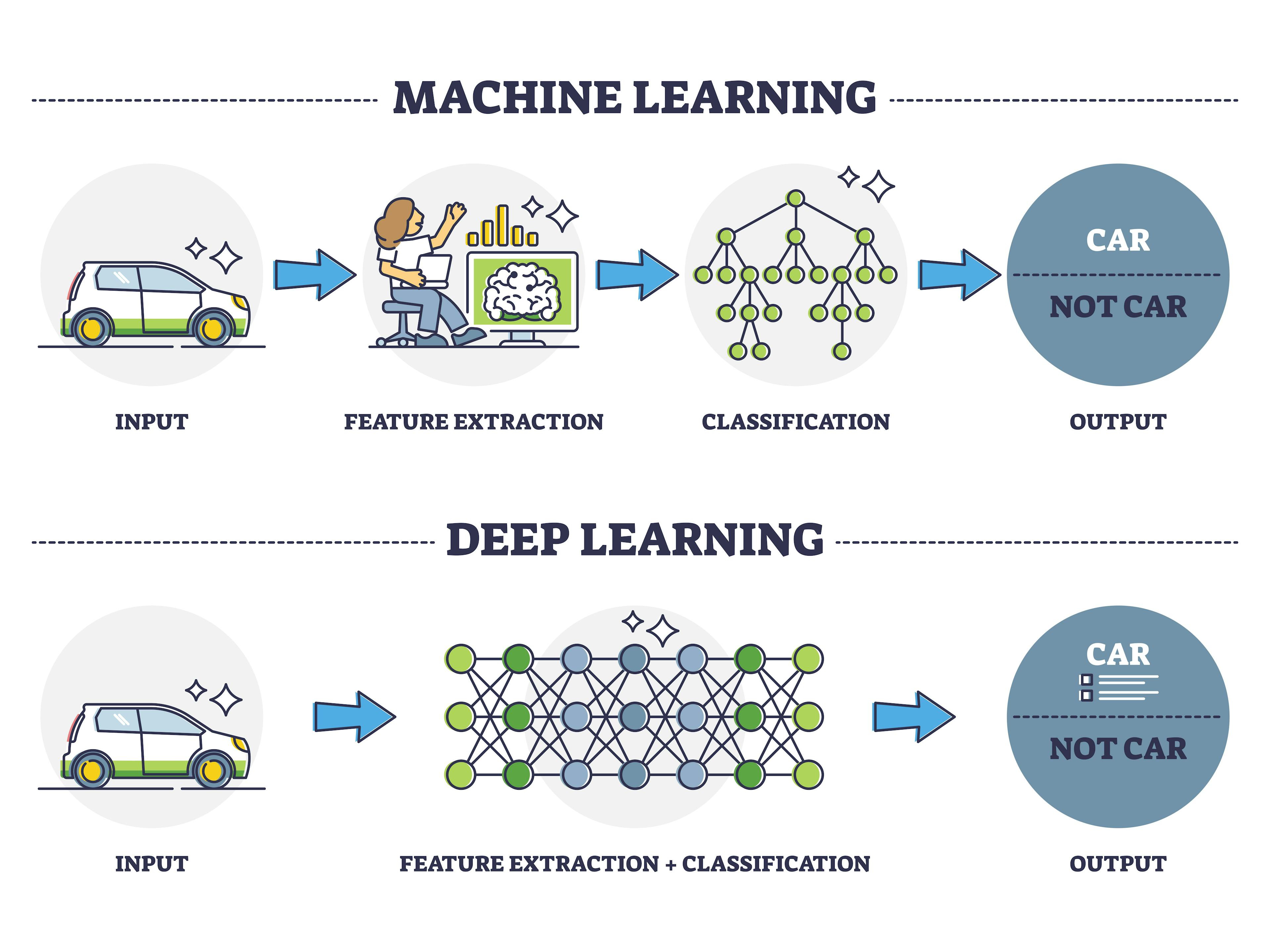
Now, if we look back at the four machine learning methods above, Deep Learning is not a separate category, but actually enhances these approaches. Examples of neural networks that can be used with these methods include:
Convolutional Neural Networks (CNNs) are used primarily for classification and computer vision tasks. Using three-dimensional and spatial data, CNNs help classify and recognise images by progressing through at least three layers of neural networks/ nodes (the convolutional layer, pooling layer, and full-connected layer). The way CNNs progress through these layers helps it recognise larger elements and shapes, making it ideal for image, speech or audio.
Recurrent Neural Networks (RNNs) are more commonly used for NLP. It uses sequential data (like words, sentences or time-series data) to determine how the input layer should influence and create the output layer. By maintaining an internal memory of previous inputs, RNNs use context from previous data points to train its hidden layer (in between the input and output layer), where the processing, analysis and prediction take place.
Generative Adversarial Networks (GANs) introduce competition between two neural network models (the generator and discriminator). The generator artificially manufactures data outputs to pass off as real data, whereas the discriminator tries to determine what is real and what is artificial. The feedback loop helps the GAN learn and create higher-quality information. This approach can be used as an extension of clustering or dimensionality reduction methods, which focus on finding patterns in existing data. GANs are often unsupervised but can be semi-supervised as well.
Autoencoders use neural networks to copy an input and create an output from it. Take a handwritten letter or number; the autoencoder creates a lower dimensional representation and decodes it into an output digit based on understanding what that initial input looks like. Essentially, it compresses the data down to its essential features and reconstructs it, making it helpful to improve upon traditional dimensionality reduction techniques like PCA or with feature learning and data denoising in supervised classification/ regression tasks.
While a lot of companies (and “ML/ AI experts”) are obsessed with deep learning, it does come with important trade-offs. The sheer amount of data and computational power makes it overkill for many simpler business problems from both a cost and complexity perspective. The hidden layers also create "black box" models where decisions are harder to interpret than traditional machine learning approaches (not even ML engineers know what the hidden layers are doing). This can be problematic when it comes to regulated industries or trying to get the business teams to trust the decisions the models make.
Remember, transparency and communication is crucial when it comes to machine learning!
All in All
Machine Learning is complex.
It is both analytics and AI. It has multiple approaches and methods. All the while, the number of algorithms that data scientists use is only growing.
So don’t try to understand everything about it.
Just remember Machine Learning is an approach to doing analytics in a more efficient and effective way.
As with any approach, there are different ways to achieve success, so finding the right one is more important than understanding all of them (or taking the most complex path because OpenAI or Google are doing it).
With ML comes AI, so in the following article, we will explore the different AI approaches companies take and what may also exist or become popular. Enjoy your week and tune in next time!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). And if you are interested in consulting, please do reach out. See you amazing folks next week!
What kind of ML Model will be one that is the objective of "Investment Optimizing in Online Channels?"
Beautiful...!