



Issue #27 – The Data Product Deep Dive (Part 2 – The Supply Chain)
Examining the supply chain that should underpin your Data Product delivery process

Read time: 14 minutes
Last week, we dug into what data products are. This week it’s time to explore the next layer down.
What do I mean exactly?
Like any real-life tangible product (e.g., clothes, a couch, the computer or phone you are looking at right now, etc.), there is a process to create it. We call this the manufacturing process or supply chain.
This is no different for Data Products. Actually, it might be even more necessary due to the complex interdependencies between data ecosystem domains that ensure a Data Product’s success.
This article aims to break down the underpinning data foundations and the supply chain required to deliver useable analytical data products.
It is worth noting that in the following article we will further discuss how to operationalise data products, so don’t miss that one too!
Quick reminder of what Data Products are
Before diving in, we must briefly explain what we are building.
As I’ve mentioned, data is a dynamic ecosystem in which each domain contributes to, and is influenced by, the whole. This ecosystem contains different types of participants and stakeholders, marked by complex relationships between users and producers. Therefore, you must take a holistic approach encapsulating the data landscape and the larger business context.
This is why, in the last issue, we defined data products as tools or solutions from which end business users can draw insights and make decisions.

Some popular examples of data products are:
Dashboards – Visual interfaces that consolidate and display key performance indicators (KPIs), metrics, and data trends in real-time
Reporting Tools – Technology that generates structured reports, often summarising historical data and providing analysis based on business requirements
Self-Service Analytics Platforms – Tools that empower non-technical users to explore, analyse, visualise, and use data independently
Predictive Models – Analytical tools that use historical data and machine learning algorithms to forecast future outcomes, trends, or behaviours
Automated Decisioning Engines – Often leveraging predictive models, these automated algorithmic solutions integrate with technologies to make decisions without relying on human interventions
AI Products – Applications or systems built on machine learning/ artificial intelligence technologies (e.g., natural language processing, computer vision, large language models, etc.) to solve complex problems, enhance user experiences, or automate tasks. These products learn from data and adapt to new information to provide better results for the user

This does not include datasets that can be monetised to external customers, which also could be defined as a product. However, for the sake of simplicity, we will not consider those types of products as they are far more niche in how they are marketed (even though the supply chain is relatively similar).
Contrary to the data-as-a-product perspective, I view these solutions as the products and the data that feeds them as raw materials. These data raw materials are processed and curated to enhance the value of the end products that business stakeholders use. This is the premise of the Data Product Supply Chain.
Foundational Data Product Components
Before we unpack the Data Product Supply Chain and manufacturing process, we need to understand its foundations

Even the supply chain process for physical products has foundations: product designs, raw material contracts, manufacturing equipment, sales/ distribution agreements, etc.
So the Data Product Supply Chain should have foundations as well. For simplicity, I have outlined four foundational capabilities that you should have in place before designing, building and productionising your data products:

1) Strategic Alignment
Too often, teams build products for the sake of it. Don’t! The first step is understanding the broader business goals, the data strategy that underpins that and the needs/ use cases of your business stakeholders. How will the product drive value for the company? What targets/ goals will it help achieve? How will stakeholders use this product? To ensure the product will be strategically aligned, interviews and workshops with business leaders and stakeholders will be necessary from the outset. This doesn’t end with the discovery phase; book check-ins and updates with these stakeholders to facilitate buy-in and user acceptance.


2) Infrastructure, Architecture & Engineering
The next step is the foundational tooling below the data product. Teams need to consider four things in sequence. First, what is the overall enterprise & technology architecture within the organisation? Hopefully the organisation has built their technology stack strategically and has a clear data flow from source to consumption, with the right tooling to deliver against the business requirements.
Second, build some semblance of a conceptual, logical and physical data model connected to the business model or the most pertinent business processes for the identified data products. This should be done with business analysts/ stakeholders to guarantee that the underlying data fits the purpose.
Third, think about the solutions architecture, which translates business requirements into technical specifications and functional requirements, specifically how the data product design/ build will align with the organisation’s infrastructure. This work builds on the data modelling/ architecture by focusing on the last-mile elements of the data product design. It is paramount to connect your underlying data assets to the curated/ derived layers and then to your data products/ solutions in a streamlined and scalable manner.
Fourth, you have the engineering. Leveraging the designs in the data modelling and solutions architecture, the engineering team should be able to design and build the required data assets and derived/ curated datasets. Engineering ensures the data is available without significant cleaning work for data analysts/ scientists
3) Data & Product Governance
Governance isn’t just foundational compliance processes; it’s about ensuring your data and underlying products are built with quality, security, scalability, and usability in mind. Frameworks should outline ownership for products, linking those to relevant data owners & stewards. Aligning this ownership with the overall data model and solutions architecture helps create transparency in the data lineage mapping and provides the basis for proper documentation, empowering business users to get value from existing data. Data governance specialists also ensure any data product design aligns with regulatory requirements and user needs.
4) Data Management
With the governance established, data management is required to maintain the quality of data feeding into the product. A lot can fall into this bucket (especially because data management is such an ambiguous term), but in this context, this should focus on master data management, data quality standardisation, and observability. While the engineering and infrastructure may build the pipelines, without management you will get the classic “garbage in, garbage out” result.
My favourite analogy for data foundations is the process of building a house. Without the foundations in place, even the nicest-looking house will sink into the ground or fall apart:
Treat the strategic alignment like the architect designing the home, making sure the layout and structure are fit for purpose.
The infrastructure, architecture, and engineering are the piping, electrical, insulation, etc., that feed through the house and make things work. Without thinking about this strategically, the house will have random wires running across the living room and leaking pipes everywhere.
The data & product governance ensures the right people own each required task (you don’t want a bricklayer remodelling a kitchen), and they all come together to deliver the right outputs.
The data management angle is having the right tools and raw materials to deliver the end product. The wrong wood or paint colour can completely ruin any build, like incorrectly managed data can do for data products.
The Original Product Supply Chain
With the foundations in place, we can begin to unpack the Supply Chain that is built on top of it.
However, I don’t want to dive straight into the ‘Data Product’ Supply Chain. Instead, let's examine the supply chain of a physical product, something that most people should conceptually understand. This will provide a tangible analogy for creating and distributing data products.

The supply chain of physical products is broken down into six steps:
Receive Order – The manufacturing process begins when a customer places an order. This might be a bulk order from a retailer, a custom/ bespoke order from an individual client or an ongoing production run. This stage sets the requirements and expectations for the entire product design and development process.
Design Product – With the order received and the specifications outlined, designs are updated or created. This is also where requirements and specifications are architected, usually using CAD software. In addition to the product function/ look, effective designs consider manufacturability and cost-effectiveness.
Source Raw Materials – The next step is to secure the materials against the design specifications. Whole procurement teams identify required raw materials and quantities, select suppliers based on a delicate balance of quality, cost, and reliability, and order/ facilitate the delivery to the manufacturing facility. Just like data, the quality of raw materials makes or breaks the value of the product being produced.
Manufacture Product – Transforming raw materials into the final product via production lines. This includes prototype design/ approval, quality control, product assembly, testing, and packaging. A lot of manufacturers practise lean manufacturing to minimise waste and maximise efficiency. While this has similarities to agile, the agile methodology is more about flexibility and responsiveness.
Distribute Product – Once manufactured, products are distributed to their intended destination. Logistics teams plan the most efficient routes and methods of transport, with inventory management systems tracking products through the distribution process as they are shipped.
Customer/After-Sales Service – The supply chain process doesn't end with product delivery. Providing customer support for inquiries or issues and gathering feedback to improve future products is crucial to creating a strong positive experience for the customer. This leads to loyalty, repeatable purchases, and positive reviews.
The Data Product Supply Chain
I’ve made up the term ‘Data Product Supply Chain’. I googled it and nothing really came up.
So I decided it should exist to help clarify a gap in how people approach going from raw data to meaningful business insights.
There are three components of this:
The Data Lifecycle
The Data Product Supply Chain
Operationalising Data Products
I’ve already written an article on the Data Lifecycle. This standard process encapsulates the stages through which the data flows, from its initial creation/ acquisition through various phases of processing and utilisation, to its eventual consumption, archiving and deletion. Here, I’m not worrying about how you do it, just that you know how to go from A (data generation, storage and processing) to B (serving and analysis) to C (reintroduction, disposal, or archiving) while managing it throughout.


The other component I won’t touch on here is Operationalising Data Products. I will go into this in the next issue (designing, building and operationalising individual data products in a stakeholder-driven manner).
Still, the critical difference between the Supply Chain and Operationalising is the scale we are talking about—building individual data products is different than establishing the supply chain that supports the continual development of all current and future data products.
In other words, you don’t build a factory for a single production run, you design it for flexibility, scalability and efficiency.

That leaves the final component, the Data Product Supply Chain.
Some people may refer to this as the Data Product Value Chain, but I see that as an amalgamation of the Data Lifecycle and Operationalising Data Products because it focuses on how data is transformed from raw capture to analytical data products and any operational steps to enable that. These definitions are helpful but miss out on the solutions architecture and underlying technical elements underpinning the data lifecycle or operationalisation process.
So here are the four phases and seven steps within the Data Product Supply Chain:

Discovery & Design – These steps exist within the operationalisation of data products but in this case we consider the whole ecosystem (multiple products, assets and models), not just discovery and design for one product on its own
Business Stakeholder Requests – Like a standard supply chain, it begins with receiving the order. There will be many orders within data, so prioritisation and alignment to the overall data strategy/ business needs are crucial. These initial requests illuminate pain points, highlight opportunities and define the problems data can solve. This step aims to take a holistic view of the business’s needs, constructing an iterative view of how these requests should make their way into the data product supply chain/ manufacturing process.
Solutions Architecture Design – This is a foundational element but also exists within the supply chain. Taking the business request/ requirements, architects craft high-level designs that outline how data will flow, connect within the platform (from data assets to curated data sets) and feed into data products. The solutions architecture design considers scalability, integration points, and the technology stack required to deliver data products robustly and allow them to evolve with your organisation's needs.
Underpinning Data Asset Layer – Data Assets provide the opportunity to build foundational datasets and tables to enable reusability and scalability. This removes the need to create bespoke foundational datasets for every data product, increasing efficiency and ROI
Source Data (Raw Materials) – Any supply chain begins with the raw materials. In data, that means ingesting and aggregating the raw sourced data. The quality and structure of this data (also referred to as the 'bronze' layer within the Medallion Architecture) will vary, but should made accessible to allow for cleaning and standardisation. Often this is not the case in organisations; this is similar to trying to manufacture a car and not having access to the rubber that makes the tires…
Develop Reusable Data Assets – With an understanding of the business processes/ solution architecture and the source data, teams should look to build reusable data assets. This is similar to creating the 'silver' data layer, which consists of clean, standardised and conformed data that aligns with the conceptual and logical data model. The data assets should reflect your most essential data subjects (e.g., customer, sales, product), constructed in a way that multiple derived/ curated datasets, business use cases and data products can pull from a single data asset (I will do an entire article on data assets in the future). By developing common data facts and dimensions in this way, organisations can dramatically increase efficiency and consistency in how their data assets connect to data products.

Understanding how data goes from raw to curated is crucial. Unfortunately, this process doesn’t always happen in organisations…
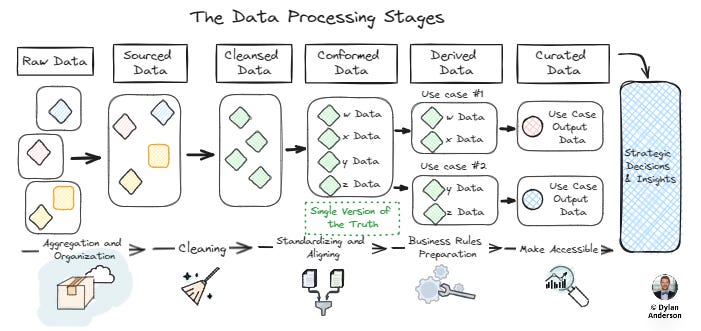
Curated Data Feeding into Data Product – At this stage, the data is specifically curated for the designed data products, and the products are finalised, packaged up and shipped to consumers (aka business users)
Curated Datasets within Data Marts – Manufacturing organisations speed up production by creating specific moulds of products that feed into the machinery. These are the derived and curated datasets in data (i.e. the ‘gold’ layer). Here, data is aggregated and transformed by analysts to specific formats required by the use cases. It might also be optimised for query speed/ accessibility or combined with other source data/ data assets to improve its value. This data might exist in Data Marts, which serve as a landing zone before the data is served to the data products and analytical solutions.
Consumer-Facing Data Products – The culmination of the supply chain process is the creation of consumer-facing data products. We outlined the popular types of data products earlier; the key thing to remember is that they are accessible and built to the stakeholder’s needs. This requires linking the curated data sets to each product, underpinning it with proper technology and ensuring orchestration (e.g., Orchestra) between data management, engineering and visualisation tools. Again, we will go into more detail on this process in the following article.
Customer Support – The data team should provide overarching, enterprise-wide training and support, incorporating feedback/ queries into overall data product design and delivery. Within the Supply Chain, this is a functional area, whereas within operationalisation, this would be done at an individual level
Training & Support – Organisations need a baseline for data product training and support. Often they rely on the teams that built the data products to train users, even if they have already moved on to building a new product. Creating an organisational capability or assigning a product owner lead to manage this process helps standardise the support function and improve existing and future data product development to be more customer-centric.
Well, there you have it. After defining what data products are, you now understand the foundations and supply chain that should underpin them.
This type of thing is exactly what I’m talking about when I say we need to think about data more holistically and from an ecosystem perspective. When most data analysts build data products, or data engineers build data assets or datasets, they don’t consider all of the elements we talked about in this article. And that is why things go wrong or are not scalable, leading to unrealised expectations and poor data ROI.
The last thing I will mention is that given the Data Product Supply Chain is more high-level than individual operationalisation, teams need to consider the overall Data Product strategy. What products are we building? How do they align with other products? What is the logical way to build? All of these questions should be considered within the supply chain (even though they don’t fit nicely into the four foundational elements we outlined above).
Next week is the culmination of Data Product month where we will talk about how to design, build and operationalise data products. I’ve led a number of these data product build projects, so this is as best practise as I can possibly share!
Anyway, enjoy your Sunday and please comment/ provide feedback below! See you next week!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). See you amazing folks next week!