



Issue #14 - The Forgotten Guiding Role of Data Modelling
Getting to the bottom of what structuring your data responsibly really means

Read time: 11 minutes
Imagine constructing a skyscraper without a blueprint, figuring out how to lay concrete, align support beams and wire electrical in an ad-hoc way as the building takes shape. Well, this is exactly what’s happening in data organisations today…
Data modelling, the foundational blueprint of the data ecosystem, is being neglected in the rush to adopt the latest technologies and deliver quick results. And we see a predictable mess of problems being addressed with short-term engineering fixes.
What Even is Data Modelling?
According to Joe Reis (who is writing a book on this topic now) a data model is:
A structured representation that organizes and standardizes data to enable and guide human and machine behaviour, inform decision-making, and facilitate actions
Data modelling has been a cornerstone of data management for decades, essential for companies to structure and understand their data. However, in recent years, the practice has become less popular, overshadowed by new data tools and technologies. This shift reflects a short-term perspective in the data industry, where immediate results are often prioritized over foundational principles.

The core issue is that data modelling requires a deep understanding of the business, its processes, and its needs. It’s not just about the physical data structuring, drawing Entity-Relationship Diagrams (ERDs) or a one-time exercise for the tech team; it is about (as put perfectly by Sonny Rivera): “creating a shared understanding between the business and data teams”.
When done correctly, a data model provides a comprehensive view of the organization. It reveals insights and relationships that might otherwise be missed by either data or business stakeholders. It also allows data teams to build better pipelines, products/ assets, and solutions that are more stable, reliable, adaptable, and, most importantly, relevant for the business.
Conceptual, Logical and Physical Data Models
I’m not a technical person, so data modelling was initially a scary subject. Given its historical evolution from database design, there is a widely held perception that data modelling is a highly technical domain about linking data types and entities.
But believing this stereotype is like shooting yourself in the foot when it comes to delivering a successful data program.
Instead, data modelling is actually the link between the business model and the physical data.
It represents the act of translating the business processes into relationships between data assets and entities. Data evangelists always talk about how data is the embodiment of how a business functions and can shed light on the finite details that underpin the KPIs businesses are built on. Well, data modelling helps get us into that detail without losing sight of the overall business (something that is done way too often).
This is done in three phases: (1) Conceptual Modelling, (2) Logical Modelling, and (3) Physical Modelling.

The first phase is the development of a Conceptual Data Model based on the highest priority business processes. Working with business stakeholders, the goal is to map out how the organisation creates, delivers, and captures value in its most common or valuable business processes. Then, map out the data points within that process. By layering the data assets and flows overtop the business logic, you create a high-level representation of how organisational data operates to drive revenue or increase sales. You know how people mention not linking data to the business value, this is how you model it out!!! Within the Conceptual Model, you should identify key data entities & domains (e.g., finance, marketing, customer, etc.), mapping the high-level relationships between them. The whole Conceptual Model should be understandable by business stakeholders as it acts as the bridge between business processes and data development.
The second phase is a Logical Data Model that starts to define the relationships between the data tables and entities within the context of the selected business process. Going one level deeper than the Conceptual Model, the Logical Model further defines the data types, attributes of each entity and the nature of the relationships. An example of this is the identification of candidate keys to identify the data entities and the primary keys that link the different entities together. While you start to get into the technical details here, the Logical Model is still independent of any technical implementation (and therefore tech agnostic). Instead, this step is focused on creating a clear structure (through ERDs or UML) for how data is related and organised. At this point, a business stakeholder might still understand the business processes and can still feed in to validate the relationships. The design also optimises for efficiency, consistency and standardization of the data, so it isn’t misrepresented or duplicated, which is very common when engineering pipelines are built without this aid.
Finally, the last step is defining the Physical Data Model, where the design is translated into technical specifications for implementation. The physical model maps the logical data structures onto the physical storage devices, describing all physical details needed to build a database. This needs to be an iterative process of detailing the specifics (e.g., database tables, column types, relationships, indexes, partitioning schemes, data constraints, etc.) with a view to optimizing performance and storage. At this stage, the implementation gets technology-specific, and different approaches would be taken based on the technology stack. No matter the stack, tooling like SqlDBM or Erwin Data Modeler can translate a physical model diagram into SQL code to save time. After setup, the Physical Data Model sets the blueprint for how data is stored, structured and accessed within the organisation, which is crucial both for organisational understanding and allows for further scalability when new data sources are inevitably added or business rules change. This needs to be proactively managed (usually by a database analyst/ administrator), with a view that an optimal configuration of the physical model (in coordination with the conceptual and logical model) provides increased data efficiency and usability.
These three data model layers work together to provide the high-level and lower-level detail necessary to optimise an organisation’s data.
Doing this is an investment, but it provides a structure for engineers, analysts, and other data professionals to save them time and effort in the long run.
I’ve never met an organisation that doesn’t want improved data quality, greater data trust, and increased relevancy to business processes, and data modelling is fundamental to achieve that.
Different Approaches to Data Modelling
I would be remiss to write an article on Data Modelling without mentioning and defining the different approaches that most teams take to physically modelling data.

It is worth noting that some people will only subscribe to one type of data modelling approach. This is slightly short-sighted, as they all have their benefits and can be applied flexibly if done properly. As Joe Reis talks about in his recent article, Mixed Model Arts should be a standard approach for any professional, as we will see more convergence and ambiguity when it comes to data modelling. Doing this requires customisation and strategic thinking, but can add significant benefits when driving different outcomes.
Kimball – One of the most popular modelling approaches. Kimball uses a star schema design for data warehousing where a central fact table is connected to multiple dimensional tables. This method is simple to understand/ implement, efficient for simple querying and works well with BI tools. On the flip side, it might require more storage due to denormalization and can be less flexible for more complex relationships, making it more of a challenge to update and maintain.
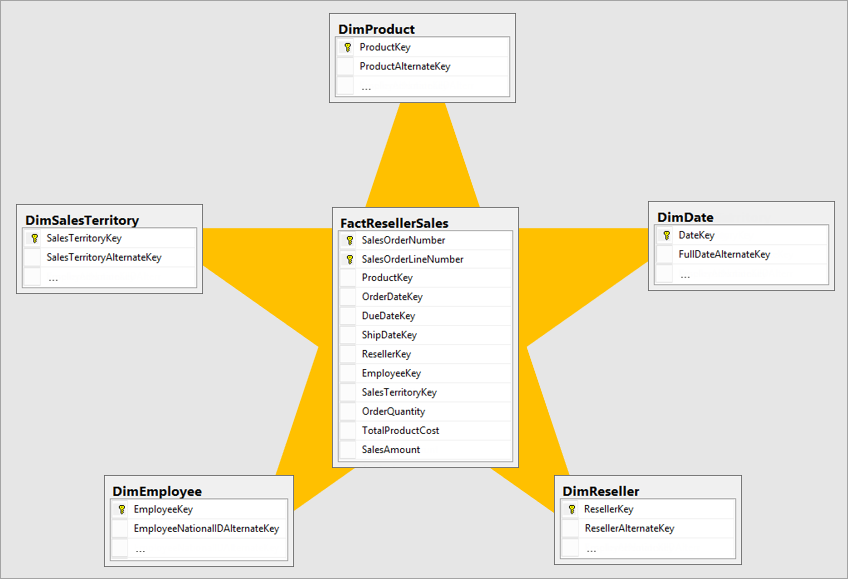
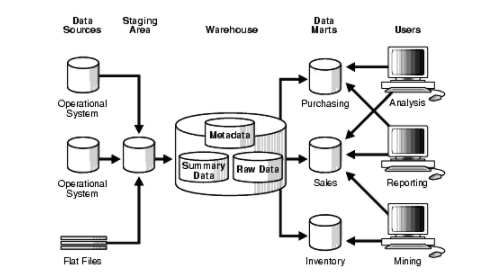
Inmon – This top-down approach focuses on creating a centralized, normalized data warehouse that serves as the authoritative data source (aka single source of truth) across the enterprise. The data model keeps data in the 3rd Normal Form to reduce redundancy and duplication of data. To increase flexibility to changing business requirements, data marts are built for specific departments on top of the data warehouse (which still acts as the single source of truth) and organize data by subject area. The downside of this approach is it is complex, time-consuming and resource-intensive. Building in this way requires more ETL pipelines, upfront design investment, higher maintenance and a strong engineering team, making it more applicable to larger organisations with complex data needs.
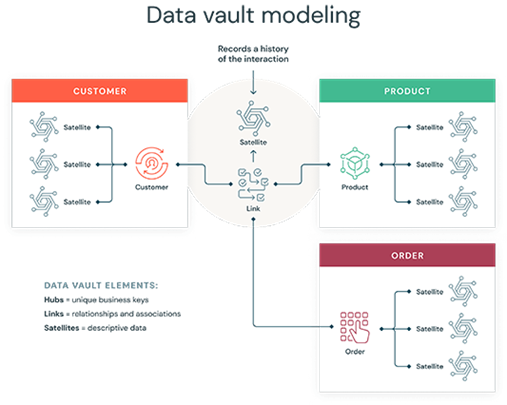
Data Vault – A more recent approach that combines aspects of Inmon and Kimball. Data Vault prioritises scalability and flexibility through a modular design. A hub-and-spoke architecture separates data into hubs (core business concepts), links (relationships), and satellites (contextual data on core business concepts), and allows for changes without disrupting existing structures. The tracking of metadata through satellites improves transparency and lineage of the data, allowing for easier auditability and governance to maintain data quality. On the flip side, Data Vault can be harder to understand and manage due to its intricate structure, making it more difficult to set up and maintain.
One Big Table (OBT) – This approach consolidates all data into a single, flat, denormalised table. This simplifies data retrieval and reduces the need for complex joins, improving access for data analysts and scientists looking for the right data. It is easy to implement and works well for simple reporting needs. However, it can lead to significant data redundancy and storage inefficiencies, and it struggles with scalability and performance for large datasets. This might be a better approach for smaller organisations without skilled engineers or large amounts of data.

BEAM (Business Event Analysis & Modelling) – The final approach is BEAM, a variation to understanding requirements for Kimball physical modelling. For that reason, BEAM focuses on modelling business processes and people to understand the data requirements. This approach ensures alignment with business needs by involving business users to define events and create data user stories. In this way, BEAM is focused on agile data modelling and helping facilitate clear communication and requirements that come straight from the business. On the physical modelling side, you then align the BEAM requirements to a Kimball Star Schema, giving a much more business-centric version of the data model. Overall, BEAM is a less traditional form of data modelling and does not necessarily match up to database design in the way others do it. It is a less familiar skill set requiring a steeper learning curve to master.
These are just high-level definitions for each data modelling approach. I highly recommend doing your research to better understand what approach fits for your use case, and how to optimise based on your specific needs. Here are some sources to help you with that (ones that I used too):
Amar Joshi – Understanding the Differences Between Inmon, Kimball, and Data Vault Data Models
Christianlauer – How to Use the BEAM Approach in Data Analytic Projects
Optimal BI - BEAM*: Requirements gathering for Agile Data Warehouses
Applying Data Modelling
There is a lot of information there and a lot more to understand if you actually want to build a data model.
Overall it is crucial to understand various data modelling approaches to effectively manage and leverage data in diverse scenarios. Each method has unique strengths and weaknesses, making them suitable for different business needs and technical environments. For instance, Kimball’s star schema is excellent for straightforward BI tasks, whereas Inmon’s normalized approach is ideal for comprehensive data integration and consistency across an enterprise.
Given how much data requirements can vary, having flexibility allows organizations to tailor their database approach. But to do that effectively, you need to understand the nuances of each approach and how it aligns with the business and data requirements your organisation has set out (for both today and tomorrow).
Unfortunately, most organisations build without a view of having a structured modelling approach. I would highly recommend against this, as data models are crucial to maintaining data integrity, optimizing storage, and improving overall data quality, which ultimately drives better business decisions and outcomes.
Without a well thought-out data model, organizations will be constantly fighting short-term data engineering problems and connecting the business needs with data requirements will be extremely difficult.
I will look to write more on data modelling and how you actually approach it, including different considerations, how it impacts data roles, and key terms that you find in the data modelling world. Look for that article in a few months!
Next week, we get into the last huge, glaring problem organisations are facing today—Data Quality. This is a huge huge huge issue, and one that will be impossible to tackle in a five-minute newsletter, but we will set the stage for what the main things to focus on should be (instead of getting lost in the despair of poor quality data)
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (not so active). See you amazing folks next week!
I had never heard of BEAM but from the brief summary I feel like I am starting to mentally toy with that concept right now.
This is timely, I have notes in my 1:1 doc with my manager for this upcoming week about how we have a need for modeling some key business processes, instead of locking that up in custom sql in a dashboard