

Issue #26 – The Data Product Deep Dive (Part 1 – What Are They)
What are Data Products? Are they datasets or analytical solutions?

Read time: 12 minutes
Data is full of confusing terms.
And it's full of simple terms that have been made confusing due to multiple meanings.
Today, the biggest culprit of ambiguity is the word Data Products.
So when I was asked to write an article on creating an operating model to deliver data products, my first reaction was, "What do you mean by data products?”

And if you know me, you know I like solving for ambiguity and taking terminology seriously (check out my whole article on data terminology). So buckle up, and let’s dig into the data product netherworld.
Different Definitions of Data Products
A lot of people are fine not getting stuck up on definitions. For example, Sanjeev Mohan writes in his excellent article on Data Products:
“One lesson we have learned is to stick to the problem statement and not get embroiled in “defining” stuff. Definitions are a slippery slope that no two people can agree on, and it takes the focus away from solving problems”
I disagree.
While we don’t have to agree on defining a data product within the entire industry, you need to define it internally in your organisation. That definition should be agreed upon between the data team and the business stakeholders who plan to use data.
If you don’t do this, you risk confusion across teams, inconsistent builds that don’t meet requirements and, most commonly, the alienation of your business stakeholders.
Internal terminology is crucial to ensuring your data program is successful, and teams are data literate.
From my research, there are two prevailing definitions of Data Products. Each one depends on your place in the Data Ecosystem.
Data As A Product
The first definition comes from the Data Mesh philosophy, which defines a data product as a high-quality and reliable data set, model or access layer product. The Data Mesh approach, which decentralises data management through different business domains, aims to treat data as available products. Domain teams are therefore responsible for productionising that data with a product thinking lens to drive usability from their data.

This encapsulates the data-as-a-product view. Given that all data is treated as a product, data is curated towards the needs and use cases of business stakeholders, allowing them to better understand what it means and how to use it more readily than in a centralised environment. In addition to this, data should have specific product characteristics, like discoverability, security, explorability, understandability, trustworthiness, etc.
Within this definition, a data product is not just a simple dataset. It does have to be discoverable (with a search engine or UI), self-describing, and trustworthy, which most datasets are not. However, a properly curated dataset with some searchability would be considered a data product in the Data Mesh definition, especially if it is built to help business users get answers to different types of business questions.
Another build of this definition I found from Zach Wilson. Zach defines a data product as high-quality data that is easily accessible via UIs, APIs, and access points, which feeds into larger systems or tools. This distinction doubles down on the need for any data product to be more than just a data pipeline or dataset (even if it is discoverable). It separates the product moniker from the pure data itself. Data by itself is just a raw material, but with feature engineering (that makes it more accessible to business and data stakeholders), it becomes a product that can feed into different use cases across the organisation.
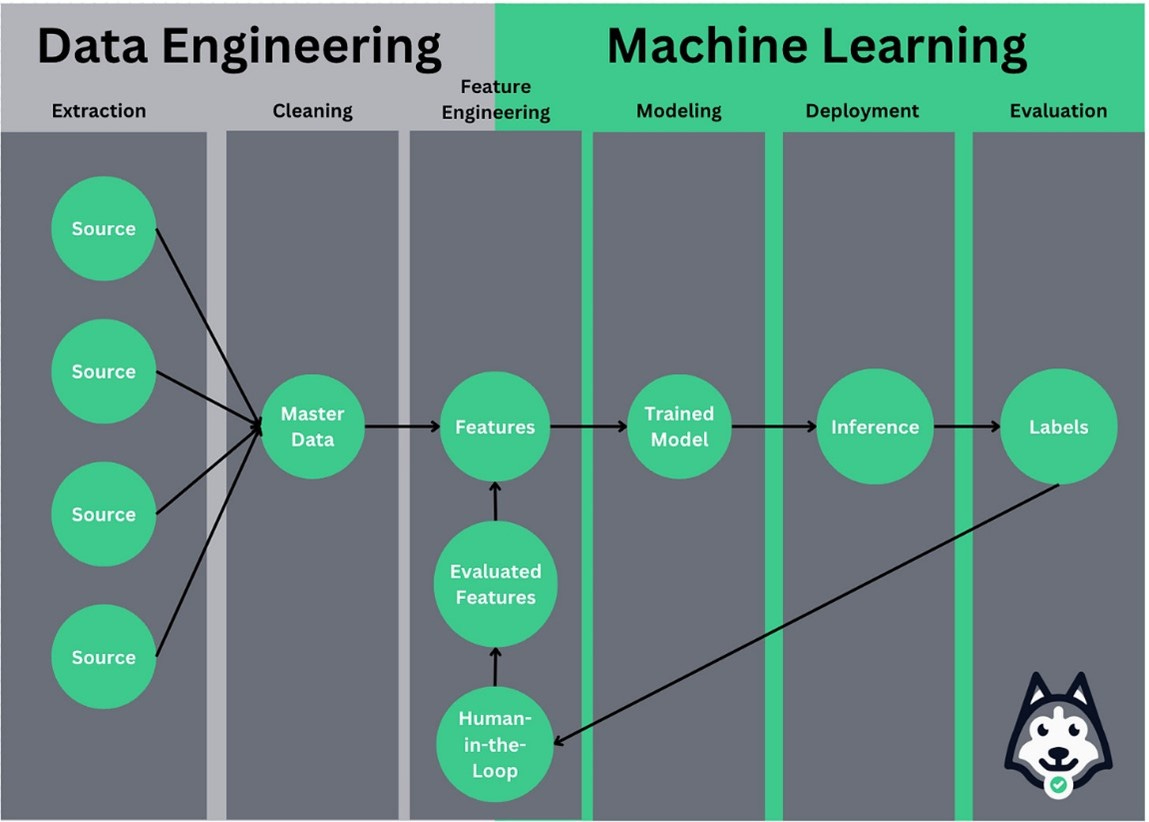
Feature engineering adds features to the master data to clean and organise the data into a product state that is accessible and usable. With data curated in this ‘product’ format, it becomes easier to search via SQL or link to analytical solutions like ML models or dashboards.
Overall, this definition defines data products as grouped sets of accessible, cleaned, and curated datasets that can quickly inform data or business insight.
Business Focused, Analytical Data Products
The second (and most common) definition of a Data Product is a data-related analytical solution that delivers value to business stakeholders. Before data mesh became popular and there was a heightened focus on Data Engineering, this definition made the most sense because most stakeholders who interacted with data did so via an analytical tool or rudimentary query engine. Dashboards, ML models, reports, etc., were seen as data products because that is what individuals consumed.
Jon Cooke (who knows more about this subject than I do and is worth following) describes the qualities of this perspective exceptionally well. To him, a Data Product must drive the P&L, tell me something about my business or tell me to do something in my business. This translates to:
Be targeted and specifically solve a business problem in an analytics context (i.e. has a direct business requirement).
Provide direct value to the business customer.
Not just be dataset unless it’s actually sold (e.g. on an external marketplace).
Have a product life-cycle with direct business customer interaction-feedback etc.
Note that all of the above are all Jon’s words because he wrote it so well and I didn’t want to muddy the waters. Go read his article as I would highly recommend it!
Jon follows this up with a Data Product Pyramid, which looks at the different types of products and how they ladder upwards from descriptive to prescriptive (think about the four stages of analytics)
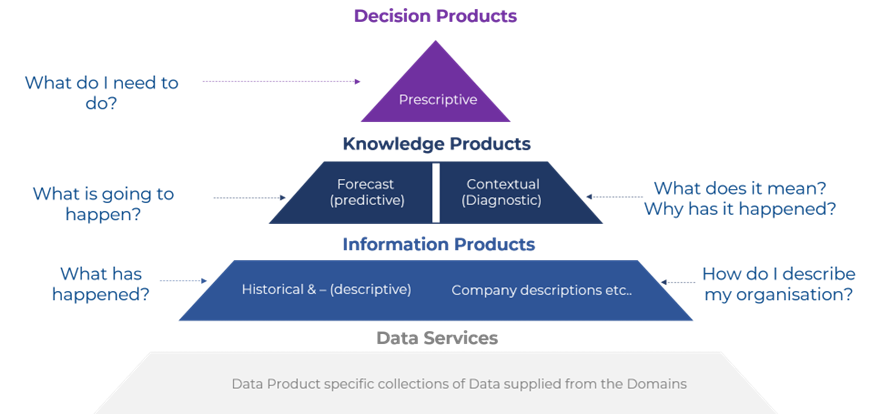
Each of these products (Decision, Knowledge and Information) is built to solve an identified business use case or problem and provide direct value to the end user (internally or externally). More tangible examples of these might include:
A Sales Dashboard that aggregates multiple datasets (e.g., customer, store transactions, products, etc.) to provide an overall view of the revenues by customer type, store location or product (Information Product – Descriptive Analytics)
A Reporting Engine built on a web app (or dashboard) that allows you to understand existing sales and forecast future sales with input levers to modify variables based on historical data or user domain knowledge (Knowledge Product – Diagnostic & Predictive Analytics)
An ML Financial Model that automates credit approval for new customers based on the ability of existing customers to pay back their loans, demographics/ behaviour of the customer, external economic factors (e.g., interest rates, consumer spending, debt loads, etc.), and internal bank asset levels. The algorithm is constantly learning from new defaults or customer payments, improving its accuracy based on new data (Decision Products – Prescriptive Analytics)
Overall, this data product definition is much more relatable for business stakeholders and non-data people. Instead of it just being curated data that can be used, these stakeholders have a bespoke dashboard, UI or algorithm that directly feeds into the business decisions they need to make, productionising the data in a way that they can use it more readily.
What is a Data Product in the Data Ecosystem?
As I’ve mentioned, data is a dynamic ecosystem in which each domain contributes to and is influenced by the whole. This ecosystem contains different types of participants and stakeholders, marked by complex relationships. Therefore, you have to take a holistic approach, paying attention to the larger business context as well as the data lifecycle and domains within it.
Within the ecosystem, a Data Product cannot be different things to different people. If that is the case, you create more ambiguity in an already complex environment.
Therefore, when talking about Data Products within the Data Ecosystem, we have to think about all the people involved—not just data engineers, analysts, or scientists but also the business stakeholders who make data-based decisions.
This requires a holistic view of a Data Product to ensure it is relatable to all people.
So, let’s define the word ‘Product’ as all people might understand it.
As the Cambridge Dictionary describes, a product is “something that is made to be sold, usually something that is produced by an industrial process.”
At face value, this aligns most with the business-focused data product definitions above within the data realm.
Unlike other business areas, the data team doesn’t necessarily sell anything other than monetising datasets, which is business model dependent (I am also not counting selling SaaS or data consulting services). The Data Team therefore should exist as a horizontal team within the larger organisational structure, enabling other departments to do their job better.
In this way, the product they sell is insights to business stakeholders.
And going back to the Cambridge definition of products, these insights are produced by the data lifecycle industrial process, which includes everything from sourcing to serving to analytics.

Therefore, in its purest sense, a Data Product must be a tool or solution from which end business users can draw insights and make decisions. To explain this in further detail, I want to provide six of the most popular tangible examples of Data Products:
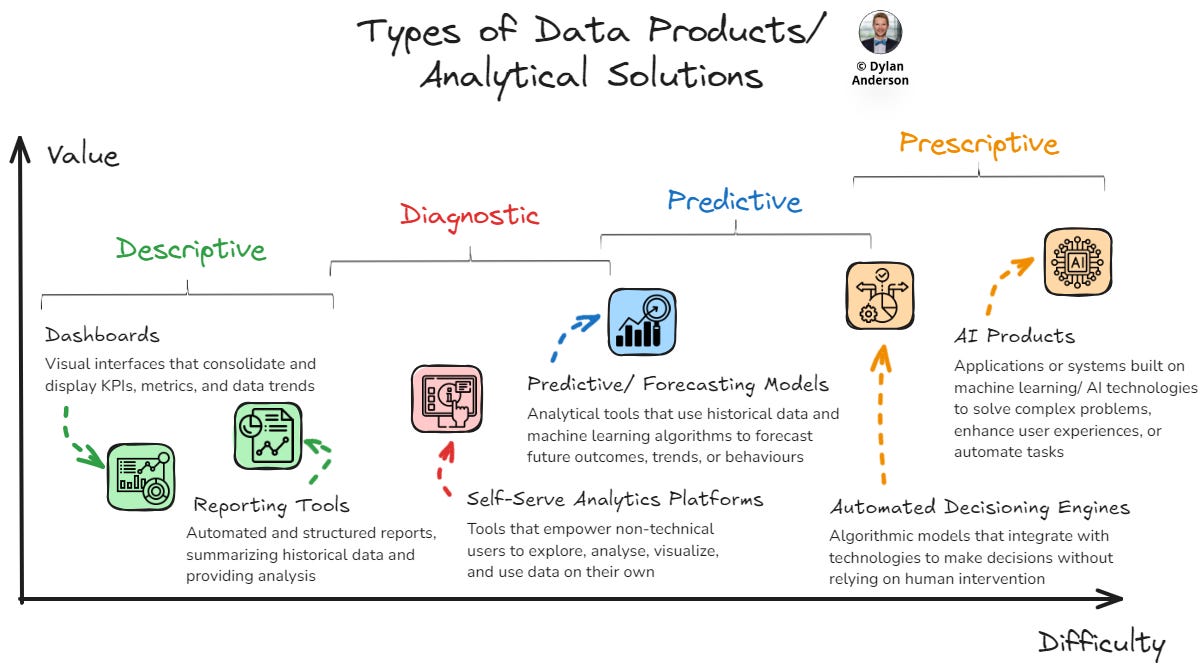
1) Dashboards
Visual interfaces that consolidate and display key performance indicators (KPIs), metrics, and data trends in real time. Designed for quick insights, usability by business stakeholders, and access to relevant data tables. Some examples include:
Executive Dashboard – Tracks overall business health (e.g., revenue, expenses, and profitability) through the most pertinent KPIs, creating a single source of truth for high-level executives
Operations Dashboard – Monitoring of supply chain metrics, efficiency and/ or inventory levels
Sales Dashboard – Consolidates CRM and sales data to show pipeline, conversion rates, and performance by region, division or store
2) Reporting Tools
Technology that generates structured reports, often summarising historical data and providing analysis based on business requirements. These reports can be automated or manually pulled when required based on parameters set by the individual. Some examples include:
Customer Reports – Segment-specific insights into customer behaviour and satisfaction to inform marketing or sales decisions
Financial Reports – Consolidation of prioritised financial metrics (e.g., sales revenue, growth, profit margin, cash flow, etc.) into timely reports
Compliance Reporting – Documentation of adherence to standards and/ or risks, usually automated or pulled to meet regulatory requirements
3) Self-Service Analytics Platforms
Tools that empower non-technical users to explore, analyse, visualise, and use data independently. These are more versatile than dashboards, are usually built with a low-code interface, and require some level of data literacy (but don’t require deep technical expertise). Some examples include:
Business Intelligence (BI) Tools – Applications that allow users to create custom dashboards and reports (e.g., Tableau, Power BI).
Ad-Hoc Reporting Tools – Integrated UI-focused tooling that business stakeholders can build custom reports based on their needs
4) Predictive Models
Analytical tools that use historical data and machine learning algorithms to forecast future outcomes, trends, or behaviours. These models can produce reports, feed into dashboards, or be set up to make decisions within technology systems automatically. Some examples include:
Sales Forecast – Prediction of future sales volume based on past performance and external factors
Churn Prediction – Identification of customers at risk of leaving a service, segmenting them based on variables linked to sales/ loyalty
Risk Assessments – Integrated models to determine the risk of a person defaulting on their bank loan, creating a decision on their application
5) Automated Decisioning Engines
Automated algorithmic models that integrate with technologies to make decisions without relying on human interventions. These products use predefined rules, algorithms, and data inputs to make rapid and consistent decisions in a real-time environment. Some examples include:
Fraud Detection Engines – Monitor real-time transactions and flag suspicious activities by applying rules and patterns learned from past fraud incidents (e.g., credit cards)
Dynamic Pricing Engines – Adjust prices of products or services in real-time based on demand, competition, and inventory levels (e.g., airline ticket pricing or hotel bookings)
6) AI Products
Applications or systems built on machine learning/ artificial intelligence technologies (e.g., natural language processing, computer vision, large language models, etc.) to solve complex problems, enhance user experiences, or automate tasks. These products learn from data and adapt to new information to provide better results for the user. The variety and categories of AI products will only increase as the field grows. Some examples include:
Chatbots & Virtual Assistants – Conversational agents that assist users with tasks, answer queries and provide customer support. These are powered by ML algorithms that allow them to learn and improve answers, which is different from classic chatbots
Image Recognition Software – Products that use computer vision to identify objects, faces, or scenes in images and videos, often integrated into existing technology (e.g., facial recognition systems in security)
Predictive Maintenance Solutions – Prediction models to determine when equipment or machinery is likely to fail, allowing for proactive maintenance and reducing downtime
More examples of data products/ solutions exist, but those six categories cover most use cases I’ve seen and remain MECE (mutually exclusive, collectively exhaustive) enough for this article.
Where does that leave the Data as a Product definition? And what is next now that we defined Data Products?
Well, I think data as a product is still very applicable today.
The Data Mesh philosophy and focus on data being curated and easily accessible as products have revolutionised how teams interact with and work with data. Instead of a swamp of raw, source data, it is now often organised in different layers, from raw ingested data to filtered or cleaned data to business-curated data that can be fed into analytical solutions. The focus on data as a product normalised this approach (also called the Medallion Architecture), promoting flexibility and improved data quality throughout the process.
For data engineers, data as a product will likely remain at the top of their minds. They work with and provide data to other data/ business stakeholders as a product. But while they may think in that way, external references to Data Products should be consistent with the business’s terminology and how others in the Data Ecosystem think about it.
The debate between terminology and the many players in the Ecosystem makes the data product definition and process a lot more nuanced. My perspective is that as data professionals, we need to understand that data starts as raw material. Like any industrial supply chain, these raw materials must be processed and curated to enhance their value. This results in analytical products that business stakeholders use and the Data Products definition we laid out today.
Given the size of this topic, next week, I will dive into the Data Product Fundamentals and Supply Chain. And the week after I will talk about Operationalising and Delivering Data Products. So tune in next week and have a great Sunday all!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (increasingly active). See you amazing folks next week!
Awesome descriptions, as always! Keep it up! I keep learning more.
Utterly brilliant article. One paragraph I'd take issue with is the below.
"The Data Mesh philosophy and focus on data being curated and easily accessible as products have revolutionised how teams interact with and work with data. Instead of a swamp of raw, source data, it is now often organised in different layers, from raw ingested data to filtered or cleaned data to business-curated data that can be fed into analytical solutions. The focus on data as a product normalised this approach (also called the Medallion Architecture)"
Having worked with Data Warehouse & BI (or formerly Decision Support System) developers and being one myself in the past - the medallion architecture concept of layering (staging > curated > business) is nothing new. It was the "modern data stack" wave which make us get embroiled with technology with shiny tools like DbT, Kafka, Spark etc, dropping focus on modelling the data in a valuable way. This was not the case prior where your choice of tech was limited (had its challenges for sure) - but you'd have 1 platform in a corporate - big DW DB like Oracle, Teradata, SQL Server, perhaps some WhereScapeRED on top - coupled with semantic layer like Business Objects Universe. The data and how it was modelled was far more of center of attention than later with things like Hadoop that solved some problems, but introduced far more others. :)