

Issue #23 – The Double-Edged Sword of Data Engineering's Popularity
Diving into the issues inherent in today's most popular data domain

Read time: 15 minutes
In 2012, the Data Scientist was the sexiest job in the 21st century.
That lasted about 5 years…
…Then people realised that the data those scientists were working on was complex, unsuitable, and involved manual cleaning. All these sexy scientists turned into janitors, swapping the lab coat and microscope for a broom and wrench.
And out of the dust, we got the part sexy, part sauve, and part pragmatic new best job in data—the Data Engineer!
What is Data Engineering?
Okay, in reality, Data Engineers have always existed under different titles, such as database engineers or administrators.
But now, their role has taken on a whole new image.
Gone is the dusty image of some IT person typing code in the background. Now Data Engineers are regarded as the do-it-all role to enable the modern data stack. They are one of the most critical areas of focus for any data team, driven by the rise of Big Data, the advent of cloud platforms and the increasing complexity and necessity of data processing.
So what is Data Engineering?
To define the domain, I want to focus on two definitions from very reputable sources.
The first comes from Joe Reis and Matt Housley, authors of Fundamentals of Data Engineering. They write:
Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering
These two were part of that cohort of data scientists turned data engineers. Moreover, now Joe writing a book in public on data modelling that you should check out.
What I love about this definition is its holistic nature; it goes beyond the DE job description and encapsulates all the other things data engineers have to think about, especially in today’s data industry (more on that later in this article).
Joe and Matt’s best infographic in the book is the DE Lifecycle.

Everybody knows that Data Engineers write code and design ETL schemas to “take in raw data and produce high-quality, consistent information that supports downstream use cases.” Unfortunately, a lot of junior engineers stop there.
The DE Lifecycle image goes beyond this and underscores the need for engineers to consider (1) how data is generated and where it flows into the system; (2) the optimal design of datasets/ tables for the analytical or ML data use cases; and (3) the notable other data domains that will strongly influence their engineering solution and its effectiveness in the data ecosystem. Regarding the last point, these undercurrents are not necessarily part of a Data Engineer’s full-time job.
However, any strong DE needs to pay attention to them and work with the relevant stakeholders to ensure those considerations are factored into the pipelines, algorithms, schemas, etc., they are creating.
The next definition and commentary come from two other DE greats, Gergely Orosz and Ben Rogojan (aka the Seattle Data Guy). They also reference Joe and Matt’s definition, adding:
Data Engineers play an important role in creating core data infrastructure that allows for analysts and end-users to interact with data which is often locked up in operations systems.
To do this, Data Engineers sit between software engineers and data scientists/ analysts to standardise, model and connect the data from operational systems to analytical solutions. This involves understanding stakeholders' requirements, designing, building and testing pipeline solutions, and ensuring they work and comply with those initial requirements. The below infographic from their article articulates a lot of the day-to-day tasks, and where engineers sit between teams, quite well.
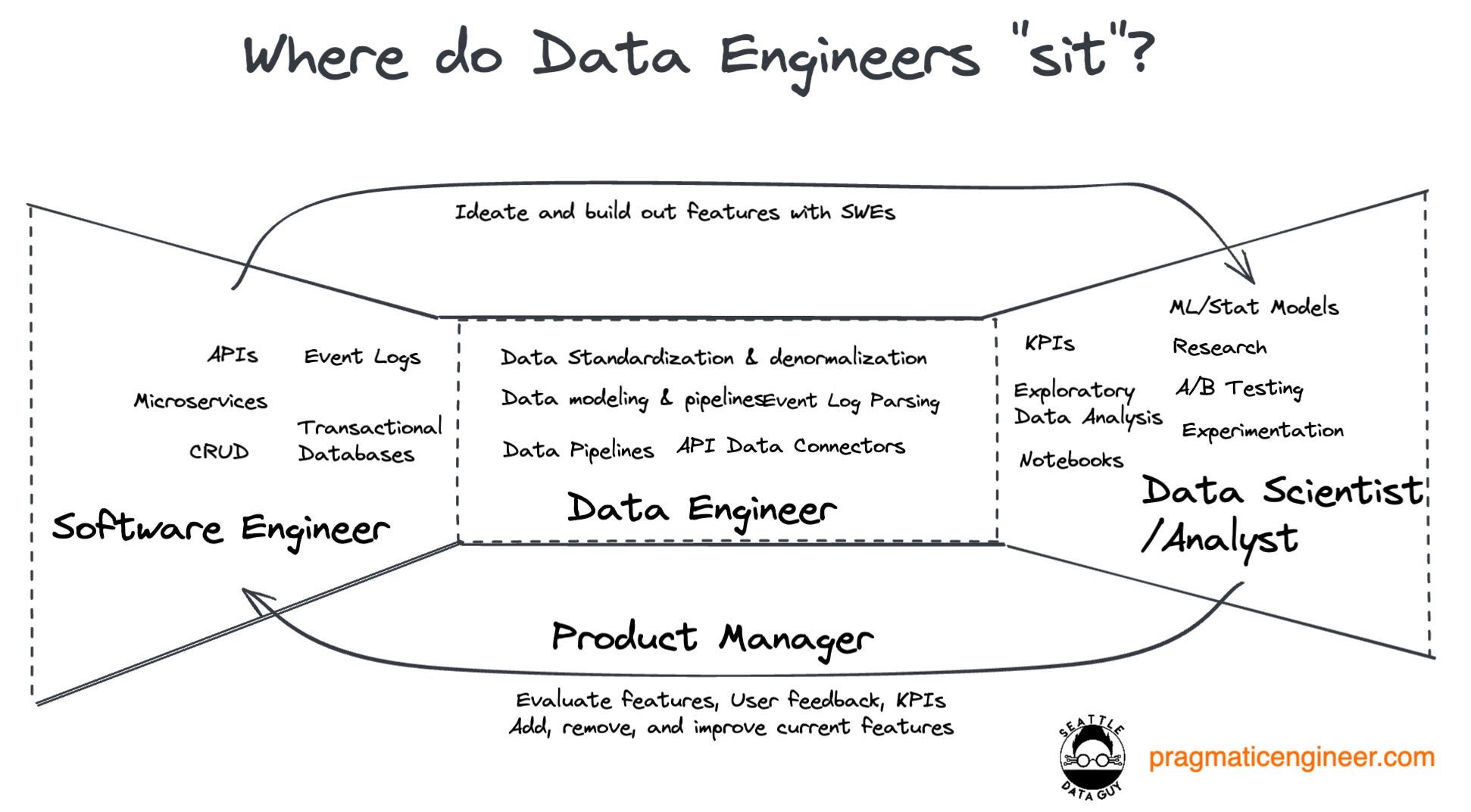
I love this simplified definition, as it gets to the crux of what Data Engineering is—creating infrastructure to make data available to end users. In their joint article, the two go on to explain relevant engineering terms (ETL, data integrity, processing, streaming/ batch, data storage types, etc.), tools, and the growing importance of the domain. We won’t go into these elements here, but worth reading up on if you need a refresher.
Before I end this section, I will never pretend I know more than any of these individuals about data engineering. This domain has many great blogs and thought leaders, especially when you dig into the issues and the technical approaches.
The Rise of Data Engineering & Understanding the Engineer’s Role
While the definitions above paint a picture of data engineering, one issue remains—specificity.
The responsibilities Joe, Matt, Gergely, and Ben describe are expansive! Referencing their definitions, engineers are responsible for:
“The development, implementation, and maintenance of systems and processes that take in raw data”
“Producing high-quality data, consistent information”
“Supporting downstream use cases”
“Creating core data infrastructure”
Understanding “the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering”
In today’s data world, no one person (or one domain) can oversee all these things!
Despite this, Data Engineers have become all things to all people within a data industry hyper-focused on doing more with less!

The biggest problem is that none of what they say above is wrong. Over the past 5-10 years, data engineering has evolved expansively. In the 2010s engineers were responsible for more low-level code development around Big Data frameworks, specifically Apache Hadoop, an open-source framework designed to manage the storage and processing of large amounts of data. With more data came more technology, meaning the engineer has had to manage the interoperability of tooling like orchestration, transformation, cloud storage, etc. These tools are now the basis of a decentralised environment focused on agility, results and building useable data products (e.g., datasets, tables, etc.) to be fed to analysts and scientists.
At the same time, companies and data teams' aspirations have grown to include real-time analytics, self-serve tooling, integrated machine learning applications, AI solutions, and many other elements. While this is a positive step for data in general, all of these solutions require one thing—clean, accessible data.
So, the burden of responsibility for this growth has been placed on data engineers.
And this won’t change. Not unless we update the existing definitions of Data Engineering to be more specific and targeted about why they need to exist.
Using the above definitions of what a Data Engineer does, I have consolidated their raison d’être down to two key responsibilities:
Reducing the complexity and friction inherent in the flow of data from source to consumption
Enabling business analysts and scientists to build analytical solutions with trusted, secure and high-quality data
These two statements can encompass a lot of tasks and activities (like the definition above), so I want to follow this up by explaining what should be a data engineer’s job vs. what shouldn’t be (and what is in between/ up for debate).

Definite Data Engineering Responsibilities – The role requirements that are relatively standardised across organisations
ETL/ ELT Process & Schema Design – Designing efficient, scalable processes for extracting, transforming and loading (ETL) data within the existing schemas and technologies
Data Pipeline Development – Building and maintaining automated workflows that transforms and brings the data from source to storage to analytical tools as per requirements
Data Integration – Working with data and technology owners to combine data from multiple sources into a unified view (usually through data assets/ products)
Orchestration – Managing and coordinating the execution of complex data workflows, including scheduling jobs, handling dependencies, and ensuring smooth data flow across various systems and processes
Performance Optimisation – Testing and fine-tuning data pipelines, queries, and data structures for optimal performance (e.g., indexing strategies, query optimisation, data storage techniques, etc.)
Version Control & Documentation – Managing code versioning for data pipelines and maintaining comprehensive documentation of the systems, architecture, and processes for consumers of the data and other platform-related roles
Grey Area Responsibilities – These tasks represent things data engineers should be supported on by other roles, but often find themselves doing it alone
Data Architecture Design – In collaboration with the Data Architect, the design of the overall structure of data systems, including databases, warehouses, workflows between tooling, etc.
Data Modelling – Creating logical and physical data models with Data Architecture and the Platform Team that accurately represent business entities and processes
Platform Infrastructure – Setting up and maintaining the underlying infrastructure for data platforms with platform architects or database administrators
Reverse ETL – Implementing processes to move transformed data from data warehouses back into operational systems
API Development for Data Access – Creating and maintaining APIs with software engineers and technology vendors to allow other systems or applications to access and interact with data securely
Data Catalogue Integration – Working with Data Governance analysts to implement connections between data pipelines and the catalogue, ensuring that metadata is accurately captured and updated
Data Privacy & Security – Integrating the necessary privacy and security measures (set by SMEs in those areas) into the pipelines (e.g., encryption, access controls, compliance flags, etc.)
NOT Data Engineering Responsibilities – The things that Data Engineers often are asked to do because of a lack of resources or non-existent org structure/ operating model. For each activity, the DE should play a role but should not own it
DataOps – Overseeing the management process of data asset, product and solution development (the flow of data from source to consumption) in a DevOps-like manner. This activity probably involves Data Engineers the most (and they will play a strong role), but there should be a delivery lead managing the process and overall programme, along with SME support in critical functions of it
Requirements Gathering – A role played by data/ business analysts, analytics engineers or product owners to collect and defining business needs for data assets and solutions (e.g., user stories, use cases, business requirements) and transferring them into technical specifications
Data Quality Monitoring/ Observability – Data quality analysts should be setting and managing the checks and stage gates across the data enterprise, including the alerting, reporting and standardisation tooling and processes
Data Democratisation – Building self-service solutions and training non-technical users across the organisation how to benefit from the use of data. Usually led by a Head of Data, programme lead, or data analytics teams
Operational Tooling Support – The technical team (e.g., IT project managers, platform/ systems engineer/ lead, etc.) owning the systems and providing ongoing support to ensure operational data sources feed into the overall data platform/ ecosystem
Data Governance Adherence – Data governance manager/ analyst who defines and implements (in coordination with data engineers) data governance policies into the platform and dataflows
There may be responsibilities and tasks missing in each of these categories (please comment if you have additional suggestions), but this shows how stretched engineers are and the huge expectations inherent in the role. This aptly leads us to the next section…
Issues Creating a Data Engineering Inflexion Point
Five to seven years ago many Data Scientists were getting fed up with their job.
They were trying to create robust ML models and do value-add analysis but kept encountering poor data quality. Hence, they had to build pipelines to automate data cleaning from operational systems.
This was the Data Science inflexion point where Scientists became Engineers en masse!
Now, I feel that there is a similar inflexion point for Data Engineering. As mentioned above, there is too much reliance on the role to do too many things. And this is only one of the big problems with the domain.
So I decided to work with Nik Walker (a human-centric Head of Data Engineering at Coop) to identify four categories of problems within Data Engineering, each with three individual issues. In a later article we will co-write how to begin approaching each to solve for it (hint: a lot of it has to do with better engineering leadership, training, and support).

Strategy & Leadership – From a leadership level, engineering is viewed as a supporting, technical foundation, limiting the direction and clarity the domain often needs
Difficulty Developing Engineering Leaders: Until you are a Staff Engineer or Head of Engineering, roles are technically driven and Individual Contributor (IC) focused. Therefore, companies don’t know how to invest in their Data Engineering leaders besides paying for certifications or coding courses. This lack of clear career progression and skill development pathways results in Engineering leaders who struggle to articulate value, manage teams effectively, or drive initiatives holistically and strategically.
No Engineering Strategy: Organizations often lack a cohesive Data Engineering strategy. Instead, they operate reactively, building pipelines and systems ad-hoc without considering long-term scalability or business alignment. This leads data models/ architectures that aren’t aligned to the business, unsolved technical debt, and designed data assets/ products that don't directly answer broader organisational business questions.
Business Leaders Don't Understand the Domain: Executives don’t understand the domain. Either they think Data Engineers can do every backend data activity (and don’t fund the supporting roles they need) or they treat DE as a cost centre rather than a value driver (and cut back on DE roles). Moreover, proving tangible value from engineering is hard. When this perception comes from the top, it leads to unrealistic expectations, inadequate resourcing, and a failure to leverage DE capabilities properly.
Technical Focus – Only the best engineers think holistically beyond the technical details, an art that is being lost with junior DEs and the advent of AI support tooling
Lower-Level Priorities of Junior Engineers: New Data Engineers fixate on learning the latest tools and technologies without grasping fundamental data principles. They focus on things like Spark, Python, and Airflow, which are all important but a lot less efficient when not combined with data modelling, schema design, and solutions architecture. You then get engineers who can build pipelines that aren’t necessarily robust, scalable or fit for purpose because they lack that higher-level thinking.
Lack of Holistic Thinking: Building on the technology focus, organisations are set up so that Data Engineers are not exposed to other domains. This results in siloed working and lack of exposure to the bigger picture (e.g., downstream analytical use cases, business processes, data quality standards, etc.). Similar to Joe & Matt’s lifecycle diagram, DEs need to think beyond the pipelines in front of them.
AI as a Crutch: AI has helped people code faster and sometimes better. But there is a growing reliance on it, especially with engineers. I’ve seen a lot of copy-and-paste code that does not consider scalable design or underlying schema logic. Especially since most new engineers don’t have that data science or software engineering background, AI is beginning to create a generation of DEs who struggle to troubleshoot complex issues or optimise pipelines for specific business needs.
Isolated Role – Despite the interconnected nature of engineers, a lot of DE departments/ teams don’t have the influence in the business they need to succeed
No Exposure to the Business: Many Data Engineers operate in a vacuum, receiving requirements through ticketing systems or project managers without direct interaction with business stakeholders. This lack of context results in solutions that are technically sound but fail to understand the company’s business model and stakeholder’s needs.
Not Encouraged to Network: Unlike their counterparts in data analysis or data science, Data Engineers aren't typically encouraged to build relationships across the organisation. We talked about isolation from the business but this can also extend to other relevant, but not connected data domains like data governance, security, management, etc. Referring back to previous points, DEs aren’t hired or trained to network so it can be hard for them to learn best practise from other experts in the organisation.
Don't Have Supporting Roles: The Data Engineering lifecycle involves multiple stages, with many organisations expecting DEs to handle all these aspects single-handedly. Even with some modelling or quality training, Engineers can’t lead on these areas and need specialised roles like Data Architects, Data Quality Analysts, or Solutions Architects to help design and implement robust and scalable solutions. Otherwise, things break, need to be rebuilt or just aren’t developed to the standard they should be.
Misaligned Perception vs. Reality – Without clarity on what they should be working on, or the data roles to support them, engineers are held to impossible expectations
Designing Optimal Systems: Within the data world, optimal only exists for a brief moment in time. Optimal systems and pipelines therefore require iterative thinking and rework due to evolving needs and technologies. Non-data leadership doesn’t usually understand this (other departments don’t change as quickly) and the necessary resources are not invested to rescope and redesign systems when requirements change.
Tackling Constant Ad-Hoc Requests: Building on the lack of strategic thinking and time spent designing systems, many companies treat Data Engineers as on-call support for any data-related issue: pipeline breaks, SQL querying, testing and validation, one-on-one stakeholder support, etc. Non-engineers also expect DEs to be available for their every whim, even for simple cleaning or querying tasks. This constant stream of urgent, ad-hoc requests disrupts planned work or project timelines, leading to quick engineering fixes rather than sustainable solutions, ultimately resulting in a dependency culture and engineer burnout.
High Cost, High Expectations: Everything about Data Engineering is expensive. The tools, compute power, and the people all carry a hefty price tag. This high cost creates pressure to deliver immediate ROI, often leading to rushed implementations or focusing on short-term gains. This is also one reason many companies defer to hiring junior engineers instead of seniors; seniors are expensive, and there is an expectation that any resource can build a pipeline.
These four categories are fixable issues, but I don’t see companies prioritising them at all. Without a serious look at how to build a data team in a more scalable way (and not fully dependent on the engineering domain), the industry as a whole will continue to face all of those symptom level issues we’ve talked about in past articles.
Speaking of scalability, next week we will dive into some of the principles of how to think about scaling your analytics. Too many companies build their data teams and technology stack as if they are 20x bigger than they actually are. Moreover, they don’t properly consider the benefits and costs of open-source vs closed-source vendor tooling. Based on a talk this week at Big Data London (if you are in town you should come through) by Deepan Ignaatious at DoubleCloud, we are going to look deeper into this and try to understand how to execute your analytical goals in a more cost-effective, faster, and bespoke way.
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (fairly active). See you amazing folks next week!
Fantastic article that encapsulates many of the challenges I see as I get more involved with Data Engineering. The investment in DE leaders is particularly acute, but goes hand in hand with lack of strategy.
A lot of the challenges in this space come from the lack of time and space C-Suite are being given to drive real change in organisations and the "football manager" approach to changing leadership when things don't go right.
This leads to DE teams having to respond to leaders expecting quick wins and not making space for crucial foundational level fixes that are often required.
Excellent article and great content and such an important topic. As you might have anticipated there might be a few different in opinions. I have just one:
1. Introducing and set up of DataOps and Data Observability capabilities, tooling and their integration with other tech in the data platform stack is not the responsibility of data engineers. I agree and I have an eventually learnt to include in the Lead DataOps Engineer responsibility in the data platform team.
2. However, using their tools and making sure that DataOps practices are followed are very much responsibility of data engineers. I also see them practicing data observability practice in their pipelines and this introduces proactive data quality controls.
Just my two cents…