

Issue #16 - The Data Quality Conundrum (Part 2 – Solving)
What to do about Root Cause Data Quality Issues

Read time: 13 minutes (sorry for the length, this is a big issue…)
Last week’s article uncovered what data quality is and where issues come from.
This week, we will tackle how to approach fixing each of them. Before we start, one thing I want to imprint into your mind is the fact below
Data quality is an output, not an input.
I mention this because data quality needs to be thought of holistically and not as a grouping of individual problems that can be tackled separately.
How do you properly address Data Quality?
Despite what many business leaders think, data quality is not something right in front of you that you can throw money or a few resources at to fix. Sure, investment will help, but it is not a surface-level issue that can be fixed with a few band-aids and a ‘get better’ kiss.

Before we get into the underlying root causes of data quality and how to properly address them, I want to cover what you shouldn’t do to solve commonly identified issues:
Rely on manual cleaning – Manual cleaning is time-consuming, error-prone, and unsustainable. It also leads to inconsistent results and doesn’t solve for root issues like broken processes or poorly designed ingestion pipelines
Do fixes offline – Offline fixes create discrepancies between live and cleaned data, making it difficult to maintain consistency and leading to potential data integrity/ validity issues when reintegrated
Only tackling raised issues – I see this a lot. Companies only tackle data quality when a ticket is raised about it. This approach is reactive and fails to identify and prevent underlying systemic problems. It should be done, but data quality teams need to go further than this (and it rarely does)
Ad hoc DQ processes/ standards – Similar to manual and offline cleaning, making processes/ standards in an ad hoc manner creates a lack of consistency and control, leading to unpredictable data quality outcomes and making it hard to enforce data governance policies
Rely on alerting software (e.g., observability tools) – Data observability tools are great, but teams often buy a new tool, deal with new problems and call it a day without addressing the underlying causes of these alerts
Place trust in a Data Catalogue or Lineage tool – Alation and Collibra are not going to solve data quality. They act as a good tool to define data definitions, sources and understand any transformations, but if business teams aren’t using the catalogue (as most often don’t), then what is the point?
These solutions aren’t necessarily wrong (you will always have to do some manual level of cleaning), but they are short-term and lack scalability. Most organisations don’t have a data quality team or approach, hence their fixes are offline, ad hoc and done with varying standards. Or organisations spend a bunch of money on a catalogue or observation tool and don’t do the proper strategy to roll it out effectively and nobody uses it or acts upon it.

So let’s get into how to properly address the root causes of data quality issues.
Before I start, I want to say:
There is no silver bullet method of fixing your data quality. There will always be issues and those will have to be tackled from multiple angles. So don’t buy into the marketing and hype of a ‘one-stop shop’ data tool!
Instead of a silver bullet, try many bullets. Plus maybe a sword, some magic, and an F-22 Fighter Jet.
The key is to arm yourself with the right weapons to tackle any situation. Consider not only the technology or processes to automate but the strategy to set the scene. For this reason, I’ve broken my approach into three overarching categories, each with 3-4 approaches within it:
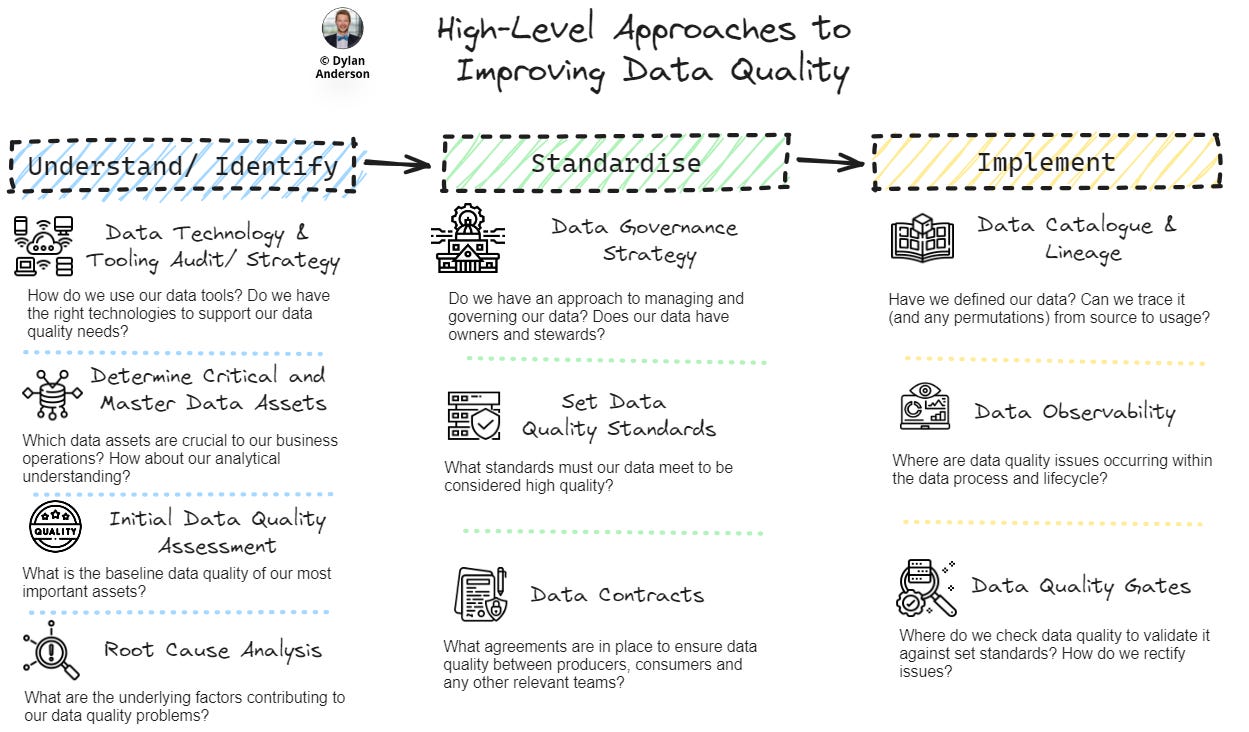
Understand & Identify the Lay of the Land – The first category is about gaining a comprehensive understanding of the existing data landscape from a technology, issue identification and data assets perspective. Unfortunately, most organisations skip this, deciding instead to jump straight into implementation or strategy setting. This is a mistake. You need to understand what you are trying to fix before you spend hundreds of thousands of dollars to fix it, especially given how complex the data ecosystem and tech landscape is! Here are the three components/ approaches to focus on:
Data Technology & Tooling Audit/Strategy – An underrated and persistent issue in most organisations is the existence of a mishmash of technologies and tools working with data. Different systems produce different types and formats of data. This gets integrated into different storage and processing tools by division, function or business unit, which then flows into different end user tooling (e.g., Excel, Tableau, Power BI, etc.). Convoluted pipelines and rules underpin this maze of technology interoperability. At the outset, organisations need to assess their data tooling landscape to identify gaps, redundancies, and opportunities for improvement. By understanding the existing technology stack, organizations can identify how data flows through different technologies, and ensure they support data quality objectives. Here teams should build a technology ecosystem framework that outlines what different tools do within the data journey. From here, data quality and management teams can craft a strategy to align these technologies with data management processes and principles and understand the implications tech will have on data quality.
Determine Critical and Master Data Assets – Doing data quality across all your data is not realistic, yet companies approach it this way anyway. A core first step needs to be identifying and prioritizing the most important data assets that are critical to both (1) business operations and (2) analytical decision-making. To do this, determine the most important business processes (e.g., revenue drivers, operationally contingent) where data is involved. Identify what data feeds into those business processes, where that data is located, how it is accessed, the data owners/ stewards and what data quality (and security) standards it should be held to. Overall, this helps focus efforts and resources on the most impactful data. Not only is this helpful for data quality, but also data security, master data management, analytics, and so many other areas.
Initial Data Quality Assessment – After releasing the v1 of the framework to LinkedIn, Piotr Czarnas (mentioned below) chimed in with another step to ensure it is clearly called out—an initial data quality assessment. I caved and ruined my pretty 3x3 framework by adding this row. The key point of this initial assessment is to gather the baseline quality of your most crucial data. Use the identified critical and master data assets as a starting point for this. Then interview stakeholders to understand where the data comes from, how much it is used, how much stakeholders trust it, and where there are problems. This gives you a rough qualitative baseline of the quality of the data. Then you can dig a bit further with any quantitative assessment methods like validation checks, data profiling or statistical analysis. If you haven’t defined the data quality standards, note that this assessment will be rough and directional (rather than comprehensive), mostly helping point you to the root causes (defined below) or the biggest problem areas.
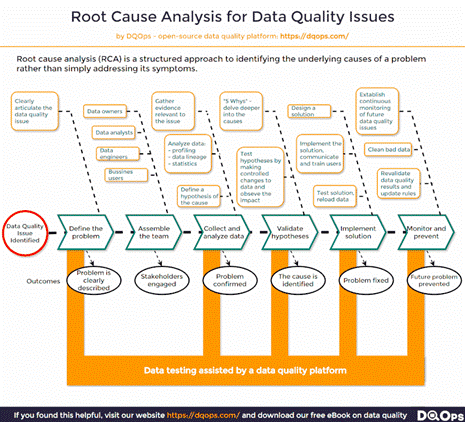
Root Cause Analysis (RCA) – As I mentioned last week, there are multiple root causes of poor data quality. To better understand these root causes, I suggest doing a Root Causes Analysis (this would build on top of your initial quality assessment). Within the RCA you need to (1) define the data quality issue with key stakeholders, (2) determine who should be tasked to solve it, (3) analyse the underlying problem through workshopping why these issues are happening with a 5 whys approach, (4) test and implement hypotheses to solving the root cause, and (5) monitor the situation to ensure the issues does not come back. There is a great post and infographic on this by Piotr Czarnas (I’ve included the infographic below). Overall this type of systematic process helps teams understand why data issues occur and enable targeted interventions that address more than just the symptoms. It also helps teams learn how to prevent similar issues from occurring in the future.
Create the Standards to Govern Data Quality – The second category builds on the foundational understanding to determine how the data should work within the organisation. The three approaches below are crucial to setting a long-term sustainable approach to data quality, but can often be done prematurely (e.g., setting standards without understanding the priority data assets) or haphazardly (e.g., establishing a Data Governance strategy without having the proper team or understanding what governance actually is). Let’s dig into these three strategic standardisation approaches:
Data Governance Strategy – I will do a much longer article on Data Governance (DG) in the future, but this is about understanding how the organisation works with and governs data. People often confuse DG with strict legal-like policies, but in reality, it is about defining how data should deliver value in an organisation while maintaining quality (e.g., accuracy, consistency, compliance, etc.) and being owned by the right business stakeholders. A data governance strategy defines how governance fits in and augments your overall data strategy. Overall, this is an extensive process of setting up policies and processes, all supported by a centralised team and relevant technologies. Doing this requires a dedicated DG lead, support from leadership, and engagement with business stakeholders to help define those roles and responsibilities when working with data.
Set Data Quality Standards – The eight dimensions I laid out in my article last week provide a basis for what Data Quality Standards should look like from a category perspective. Within that, you also have to look at how you implement those dimensions. For this, leverage your critical and master data assets to determine rules that will maintain their quality. Those defined rules will allow engineers to better automate cleaning within pipelines. For example, dealing with null values to promote completeness, or ensuring product names are aligned with master data assets. These standards can be implemented in multiple ways (both automated and done manually), with different methods at different parts of the data lifecycle. But the first step is establishing those clear and measurable criteria for data quality to serve as a benchmark for all people across the organisation.
Data Contracts – Data contracts are a newer idea around creating agreements between data producers and consumers to define the quality, format, and timeliness of data to be exchanged. At the core, data contracts set clear expectations and responsibilities between the downstream and upstream groups of data users, improving communication and reducing misunderstandings which ends up being one of the biggest issues in solving and maintaining data quality. By focusing on defining and enforcing the schema, structure and other elements of the data (often through automation), contracts help ensure consistency, reliability and transparency of data. Contracts also help with data entry and ensure validity across fragmented data systems throughout the data lifecycle. Expect to see a lot more happen in this area as more companies invest in automated contracting tools or approaches. Follow Andrew Jones or Chad Sanderson on this, as those two have led the way in making this concept mainstream.

A simplistic view of how Data Contracts are set up

Implementing Tools and Data Quality Checks – The third category is all about implementation. Here we get into tools and processes that monitor and enforce data quality standards throughout the data lifecycle. Companies often skip right to this stage, limiting the effectiveness of these options. To do each of these correctly, you have to implement with the business users in mind, understand the inputs/ outputs of the technology, and determine what actions or processes need to underpin them:
Data Catalogue & Lineage Tooling – Data catalogues were the hottest technology a few years ago as metadata surged and companies realised they needed to track/ understand it. And a data catalogue does just that, allowing users to search datasets, understand its content, provide access and define ownership. On the other side, you have data lineage tools (which can be found in some data catalogue offerings) that construct the data flow of data assets from source to consumption, helping users understand what has been done to the data when they access it. Both these tools are essential to data quality efforts by enhancing data transparency, helping trace data issues to their origin, and improving trust and access to the right data for business users. There is a big but though. From my experience, companies buy these catalogue/ lineage tools and don’t do enough work validating the strategy for implementation. This means that there is a lack of data ingested into the catalogue, the catalogue doesn’t hit on the business users’ needs, and adoption is low, resulting in a lot of money spent on a tool that really doesn’t provide clearly tangible value. It is a huge problem in the category, one I plan to write about in the future!
Data Quality Gates – I saw this idea and concept promoted by Piotr Czarnas (I mention his name a lot, go follow him). In a nutshell, data quality gates are checkpoints at various stages of the data platform (usually contained within pipelines) that validate data against predefined criteria before it proceeds further. These gates can be addressed in multiple ways. For example, Piotr explains the first one might be defined and managed by established data contracts, while the second could be automated data checking and cleaning using AI to fill in invalid values according to predefined rules. Overall, these gates prevent poor quality data from contaminating downstream processes and outputs by ensuring it is fixed or only allowing high quality data to be used. Rather than a tool or technology, this is more of an approach that tools or resources would support.

With automated and manual cleaning gates, data quality can be much better managed. Source Piotr Czarnas Data Observability – The last approach is a tool that is extremely popular today. Data Observability tooling helps monitor data health metrics to detect, diagnose, and resolve data quality issues in real time. The overall goal of data observability is to reduce data downtime, which is when data that is being fed into decision-making is incorrect without teams even knowing it (or where the problem is). In this sense, observability looks at identifying (1) how up-to-date (or fresh) your tables are, (2) the quality of your data going through, (3) the completeness of your data tables, (4) any changes in the schema that may lead to broken data, and (5) where any breaks or lineage issues are happening. With reduced data downtime, your organisation can rectify operational or analytical data issues faster. The biggest problem with data observability tooling is the complexity of implementation (aligning everything to all the different systems and technologies) and the willingness of organisations to pay for a view into their data quality (as the benefits of data quality are hard to quantify). I recently talked to a founder of an observability tool and she mentioned this explicitly: “How can I make companies understand why you need to pay for data quality? How can I prove its value?”

I’m going to end off here because that is A LOT of content to digest. As you can see with all these approaches to fix data quality, there are tons of interdependencies and variables that have to be considered. Solutions will need to flow across teams, and pure technology approaches will not solve the problem at hand.
Next week we jump into the framework that expands on my above statement—defining and explaining the People, Process, Technology (and Data) framework, including how to use it in multiple situations (because I’m not here to just provide ChatGPT level definitions). Tune in next week for some more Data Ecosystem fun!
Thanks for the read! Comment below and share the newsletter/ issue if you think it is relevant! Feel free to also follow me on LinkedIn (very active) or Medium (not so active). See you amazing folks next week!